- [직접 구현하는 머신러닝] K- 평균 (K-Means)2023년 11월 20일
- Cat_Code
- 작성자
- 2023.11.20.:45
오늘은 K-평균 알고리즘 (K-Means)를 Python으로 직접 구현해 보겠다
필요한 라이브러리는 Numpy 하나이다
K-Means 알고리즘의 과정을 순서대로 나타내면 아래와 같다
1. 데이터 공간에서 임의의 k개 중심점을 초기화 한다 (랜덤 선택), 여기서 중심은 클래스 또는 범주에 해당한다. 즉, 이 중심점을 기준으로 해당 데이터의 클래스가 결정되는 것이다. 이때, k는 하이퍼 파라미터로 직접 지정해주어야한다.
2. 각 데이터 관측치와 각 중심 사이의 유클리드 거리를 계산한다. - 모든 데이터와 각 중심점 사이의 각각 거리를 구하는 것
3. 각 데이터 관측치를 가장 가까운 중심의 그룹에 할당한다 - 즉, k=3이라고 가정을 한다면 1점과 data들의 거리 2점과 data들의 거리, 3점과 데이터의 거리가 구해졌을 것이다. 즉, data의 하나의 element당 3개의 거리가 구해진다. 따라서 이중 최소거리인 점을 해당 데이터의 그룹으로 할당하는 것이다
4. 각 중심을 해당 중심에 할당된 모든 데이터 관측치의 평균으로 갱신한다 - 앞에서 data들의 element들은 각각의 그룹이 할당 되었다. 따라서 이번에는 각 그룹별로 평균을 구해서 그 평균을 다시 각각의 중심점으로 할당한다.
5. 수렴 기준에 만족할때까지 or 사용자가 지정한 iter 수만큼 2~4단계를 반복한다
이제 순서대로 해당 코드를 작성해보자
가정 :
- Data = (300개의 관측치 , 2개의 특성) - 300x2의 형태
- k = 3
#data 생성 #data 생성 nPerClust = 200 blur = 0.8 A = [ 1, 1 ] B = [ -3, 1 ] C = [ 3, 3 ] a = [ A[0]+np.random.randn(nPerClust)*blur , A[1]+np.random.randn(nPerClust)*blur ] b = [ B[0]+np.random.randn(nPerClust)*blur , B[1]+np.random.randn(nPerClust)*blur ] c = [ C[0]+np.random.randn(nPerClust)*blur , C[1]+np.random.randn(nPerClust)*blur ] data = np.transpose(np.concatenate((a,b,c), axis=1)) # plot data plt.plot(data[:,0],data[:,1],'ko',markerfacecolor='w') plt.title('Raw (preclustered) data') plt.xticks([]) plt.yticks([]) plt.show()이때 , A,B,C를 중심으로 데이터를 생성해주는 이유는 정규 분포로 생성할 경우 한 곳에 모이기 때문이다.
blur의 경우A,B,C에 클러스터링 되는 것을 흐트려주는 기능으로 낮을 수록 해당 A,B,C에 데이터가 각각 모이게 된다.
위 코드로 생성된 데이터의 예시는 아래와 같다
단계1.
현재 주어진 Data의 공간에서 랜덤적으로 3개의 점을 선택한다.
이는 numpy.choice를 활용하면된다.
#중심점 갯수 k=3 #data중에서 3개의 중심점 idx 랜덤으로 선택 ridx = np.random.choice(range(len(data)), k, replace=False) #idx로 구성된 중심점 좌표 3개 centroids = data[ridx,:]ridx의 경우 = [321, 80, 124] 이런 식으로 idx가 3개 선택된다
centroids는 해당 idx의 data를 가져와서
[[-4.02713598 0.03968633] [-1.97037758 0.51064482] [ 3.19432819 3.89529453]] 으로 구성된다
단계 2.
이제 3개의 중심점과 모든 data들 사이의 유클리드 거리를 구해준다
dists = np.zeros((data.shape[0],k))이를 위해서 우선 0으로 구성되어 있으며 (데이터의 갯수, 중심점의 수) 형태의 행렬을 만들어준다
현재 300개의 관측치에 중심점이 3개가있음으로 (300, 3)의 형태가 된다
그리고 각 중심점을 순서대로 loop하면서 데이터들과 해당 중심점의 유클리드 거리를 구해준다
for ci in range(k): dists[:,ci] = np.sum((data-centroids[ci,:])**2,axis=1)그리고 해당 거리를 dists에 해당 중심점 차원에 지정해준다.
이때, 유클리드 거리는 (data - 중심점)의 제곱근이다.
따라서 이를 통해서 각 중심점과 데이터들의 거리가 구해진다
단계 3.
그리고 이렇게 구한 거리를 활용해서 해당 각 data의 element에게 중심점 인덱스를 부여해준다.
이는 가장 가까운 중심점을 부여해주는 것으로 해당 element의 경우 해당 중심점 그룹에 속하게 되는것이다
groupidx = np.argmin(dists,axis=1)이는 numpy.argmin()을 통해서 수행할 수 있다. argmin는 최솟값의 인덱스를 반환한다
즉, 현재 중심점이 3개이기 때문에 거리를 구한 배열이 3차원으로 구성되어있다. 이때, 각 element마다 3개의 거리값을 가지는데 이때의 최솟값의 인덱스를 부여해주는 것이다.
단계 4.
이제 그룹별로 평균을 구해서 해당 평균지점을 새로운 중심점으로 갱신한다.
즉, 1번 그룹의 평균이 새로운 k==1, 2번 그룹의 평균이 새로운 k==2 식으로 갱신되는 것이다
이는 아래의 코드로 수행할 수 있다
for ki in range(k): centroids[ki,:] = [ np.mean(data[groupidx==ki,0]), np.mean(data[groupidx==ki,1]) ]단계 5.
이제 해당 단계를 원하는 만큼 반복해주면 된다. 이를 적용한 전체 코드는 아래와 같다
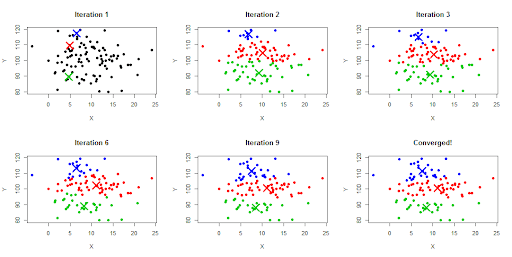
k = 3 # step 1 ridx = np.random.choice(range(len(data)), k, replace=False) centroids = data[ridx,:] # 원하는 만큼 iters = 3 for iteri in range(iters): # step 2: compute distances dists = np.zeros((data.shape[0],k)) for ci in range(k): dists[:,ci] = np.sum((data-centroids[ci,:])**2,axis=1) # step 3: assign to group based on minimum distance groupidx = np.argmin(dists,axis=1) # step 4: recompute centers for ki in range(k): centroids[ki,:] = [ np.mean(data[groupidx==ki,0]), np.mean(data[groupidx==ki,1]) ]이런 식으로 반복하다보면 아래의 사진처럼 중심점들이 갱신되는 것을 확인할 수 있다
sklearn
위 귀찮은 과정을 직접하지 않더라도 sklearn에 해당 코드는 구현되어 있다
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=3, random_state=42) kmeans.fit(data) centroids = kmeans.cluster_centers_간단하게 우리가 구하고 싶은 k는 n_clusters 파라미터로 지정해주고
데이터를 fit한다음 .cluster_centers_로 구할 수 있다.
'[CS] > 파이썬 🖤' 카테고리의 다른 글
파이썬은 왜 다른 언어보다 속도가 느릴까? (1) 2025.06.02 uv, 파이썬 패키지 관리의 신세카이 (0) 2025.05.15 GIL (0) 2023.07.25 [CS & Python] Python 동시성에 대한 Reference 정리 (0) 2023.06.24 [파이썬 - 알쓸신잡] 왜 Dict는 List 보다 빠를까? (0) 2023.06.12 다음글이전글이전 글이 없습니다.댓글