- [네이버 부스트 캠프 AI Tech] Transformer2023년 03월 21일
- Cat_Code
- 작성자
- 2023.03.21.:57
본 글은 네이버 부스트 캠프 AI Tech 기간동안
개인적으로 배운 내용들을 주단위로 정리한 글입니다
본 글의 내용은 새롭게 알게 된 내용을 중심으로 정리하였고
복습 중요도를 선정해서 정리하였습니다

✅ Week 3
목차
- What is transformer
- Encoder
- Self Attention
- Positional Encoding
- The Residuals
- Decoder
- Masking
The Residuals
The Residuals
✅ Intro

오늘 도비와 함께 배울 딥러닝 내용 한줄 요약 ⬇️
Reference
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Arabic, Chinese (Simplified) 1, Chinese (Simplified) 2, French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 1, Spanish 2, Vietnames
jalammar.github.io
1. What is transformer
온 세상이 transformer이다
요즘 딥러닝의 트렌트를 따라가다 보면 무조건 마주치게 되는 모델 방법론이 있다
바로 transformer이다
transformer가 유명해지기 시작한 것은 Google의 "Attention All you need" 라는 2017년 논문이 발표 되고 부터이다
물론 나중에 논문리뷰로 다루겠지만 이 논문은 딥러닝을 공부하는 사람이라면 무조건 한번은 읽어 봐야할 필독서 같은 논문이다
물론 논문에서 제안하는 Attention 구조는 위의 논문에서 처음 제시된 것은 아니다
attention seq2seq라는 모델에서 이미 적용되고 있었다
하지만 위의 논문에서 attention 구조만 갖고 새로운 transformer라는 구조를 제안하면서
자연어 분야에서 딥러닝의 성능이 엄청나게 증가하였다
그리고 이제는 자연어를 넘어 이미지 등 다양한 task에서도 transformer 구조가 SOTA를 달성하고 있다
최근 많은 관심을 이끈 GPT도 자세히 살펴보면 transformer 구조를 갖고 있다
따라서 오늘 배울 transformer를 잘 이해한다면 최신의 딥러닝 모델들의 구조를 이해하는 것에도 큰 도움을 줄 것이다
2. Encoder

transformer 모델은 크게 보면 Encder & Decoder구조로 나누어진다

쉽게말해서 input 데이터를 Encoder에 넣어서 이를 Decoder로 보내 우리가 원하는 Output을 만들어 내는 것이다
마치 암호화 시켜서 이를 해독하는 듯한 모습을 가지고 있다
위에 보이는 Encoder 한개는 논문에서 6개의 Encoder를 쌓아서 만든 것이다 - 물론 이는 이용자가 선택할 수있다
그럼 Decoder는 무엇일까 쉽게 말해서 Decoder들을 쌓아서 만들 것이다
이를 자세히 표현하면 아래 사진과 같다
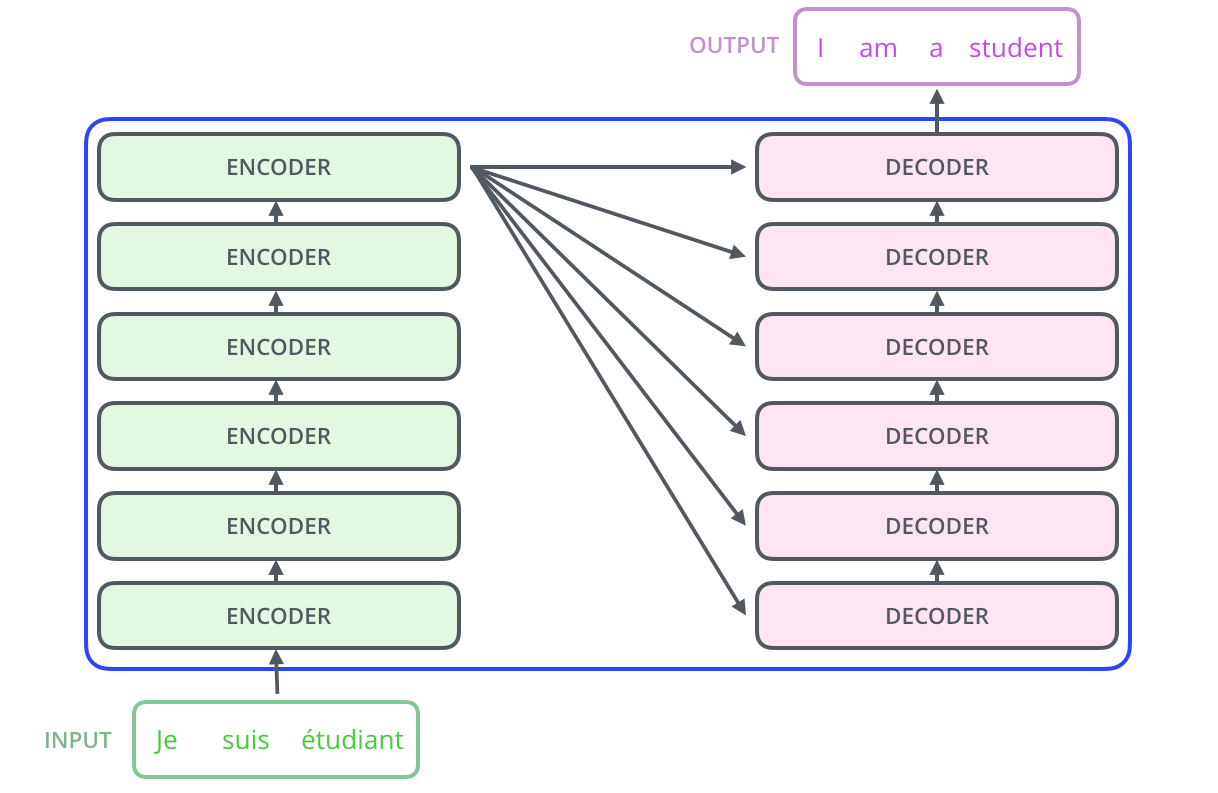
각각의 Encoder들은 모두 같은 구조를 하고있지만 이들끼리 W를 공유하지 않는다
하나의 Encoder를 확대해서 구조를 살펴보면 두개의 구조로 구성되어있다
우리는 Encoder부터 자세히 살펴보도록 하자

Encoder 구조 Feed Forward Neural Network와 Self-Attention이다
Feed Forward Neural Network는 우리가 이전부터 계속해서 배워오던 일반적인 딥러닝 모델이라고 생각하면된다
그리고 Self-Attention의 경우에는 다음 장에서 더 자세히 다루게지만 간단히 말하자면
문장을 입력받았을때 문장안에 있는 단어들의 관계를 벡터로 만들어 주는 단계이다
Self-Attention에서 만들어진 출력들은 Feed Forward 신경망을 통과하게 되고
이는 각 위치의 단어마다 적용되어 반복된다
이를 그림으로 표현하면 아래와 같다

우선 Input으로 Word Embedding된 값이 들어간다
Word Embedding을 모르면 아래 링크를 참조하길 바란다
Glossary of Deep Learning: Word Embedding
Word Embedding turns text into numbers, because learning algorithms expect continuous values, not strings.
medium.com
그리고 Word Embedding 단어는 Self - Attention을 지나면서 새로운 vector값이 출력되고 이렇게 출력된 값이 Feed forward로 들어가 output을 만들어 내는 것이다
그렇다면 Self-Attention에서는 어떻게 out을 만들어 낼까?
이를 조금더 자세히 살펴보자
🔥Self-Attention
Attention하니까 뉴진스의 attention 밖에 생각나질 않는다...
물론 우리가 transformer를 접하기 전까지 self-attention이라는 개념을 들어보지 못했을 것이다
이해하기 쉽게 개념을 설명한다면
"개가 강을 건너지 않은 것은 그것이 너무 피곤했기 때문이다"라는 문장이 존재한다고 했을때
인간이라면 그것과 개를 쉽게 연결 짖는다
하지만 기계번역에서 기계는 그러한 연결을 자동으로 할 수 없다
하지만 Self-Attention을 하게 되면 문장안에서 단어 사이의 관계를 학습하게 되고
결국에 기계까 그것과 개를 연결짓게 만들 수 있다
즉, Self-Attention은 단어 사이의 관계를 집중하게 만들어 주는 것이다

이런식으로 말이다 그럼 어떻게 연결 지을 수 있을까? 방법에 대해서 알아보자
Self Attention을 하기 위해서 중요한 건 꺾이지 않는 마음도 있지만 Queries, Key, Value이다
input으로 들어온 단어의 임베딩 벡터에서 Q, K, V 3개의 벡터를 생성해 내내다
How? 각각의 Q_W, K_W, V_W를 활용해서 임베딩 단어 벡터와 내적곱을 하여 생성하는 것이다
+)추가하면 여기서 생성되는 Q, K, V는 기존 임베딩 벡터보다 작다, 반드시 그런건 아니지만
이는 파라미터를 줄이기 위해서 줄인것이다 - Transformer의 파라미터는 엄청 크다
위의 과정을 그림으로 표현하면 아래와 같다

갑자기 무슨 Q, K, V 인가 하는 생각이 들 수도 있지만
여기서 만들어진 Q, K, V는 계산을 위해서 만들어진 것이다
즉, 도구와 같은 것이다
그럼 이렇게 만들어진 Q,K,V는 어떻게 활용될까?
바로 앞에서 봤듯이 Output으로 만들어지는 벡터를 생성하는 것에 이용된다
우선 단어가 2개인 상황을 가정하고 설명하겠다
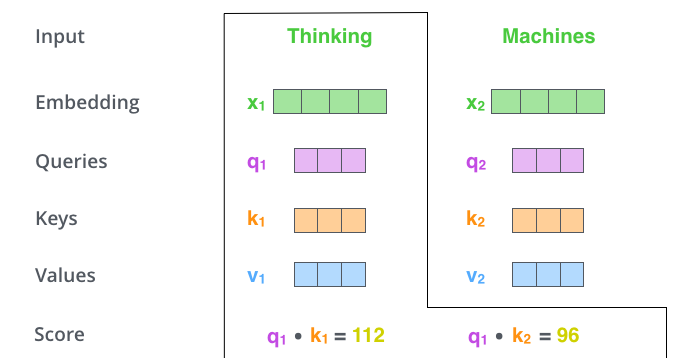
먼저 각 단어에 대해서 Q, K, V가 생성되었다고 하자
그럼 첫번째 단어의 Q1, K1, V1 있고 두번째 단어의 Q2, K2, V2가 있을 것이다
이렇게 만들어진 Q,K,V들을 이용해서 각 단어마다 Self-Attention을 수행한다
먼저 1번째 단어를 기준으로 했을때
Q1과 각 K를 전치하여 곱해준다
ex) Q1 * K1.T, Q1 * K2.T -> 내적이다
1) 결국 이렇게 하면 각 스칼라 값이 값으로 나오는데 이를 Score라고 한다
2) 이렇게 만들어진 Score를 Key 벡터 사이즈의 제곱근으로 나누어 정규화를 시키고
3)정규화된 값을 Softmax 함수에 넣어 값을 출력환다
여기서 만들어지는 Softmax의 값은 현재 단어의 위치가 각각의 단어들의 의미가 얼마나 들어갔는지를 의미한다
4)그리고 Softmax를 나온 값에 단어 각각의 Value를 곱해주고 이를 Sum 하면 우리가 원하는 첫번째 단어의 Output vector가 나오게 된다
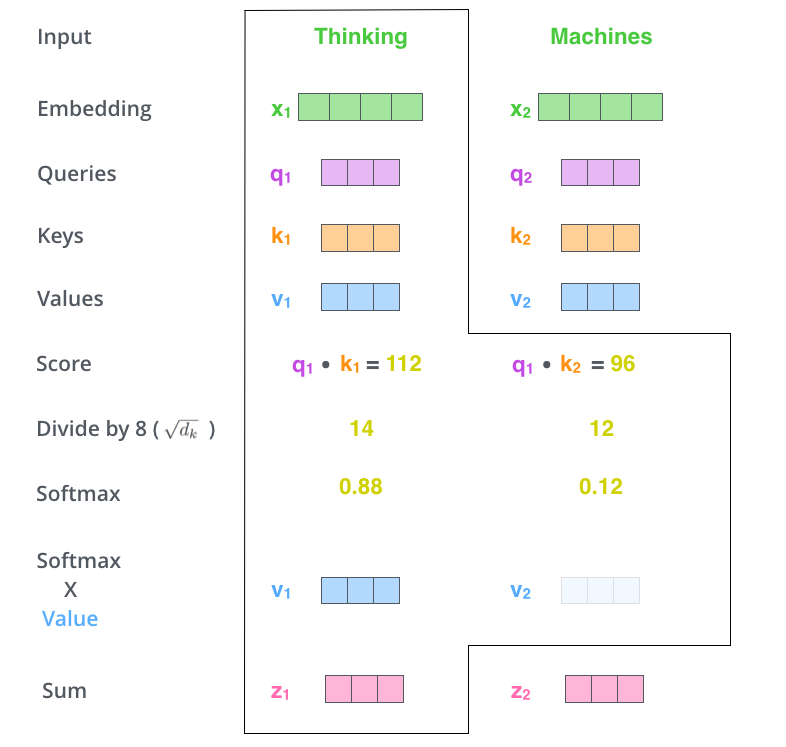
위의 과정을 그림으로 표현하면 위의 사진과 같다
따라서 이러한 과정을 단어마다 반복하게 되면
각 단어의 벡터인 Z1~t까지의 벡터가 만들어지게 된다
이것이 Self-Attention 과정이고 결과이다
자세히 살펴보면 생각보다 쉬운 과정이다
물론 이러한 과정을 왜 하는지는 의문이 있을 수 있지만
- 나도 아직 이부분이 의문이다
아무튼 효과적인 방법이라는 것은 결과가 보여주고 있다

Self-attention 한번에 정리하면 위의 그림과 같 그리고 이렇게 실행된 self-attention에 multi-headed attention 이라는 새로운 메커니즘을 추가해 모델을 더욱 개선합니다
즉, self-attention을 여러번하는 것으로 이해하면된다
이는 각각의 Qw, Kw, Vw를 사용하기 때문에 각 head에서 여러 Z 행렬이 만들어진다
그러나 이렇게 만들어진 Z들은 feed forward layer로 전달할 수가 없다
feed forward layer의 input은 한 개의 행렬만 받을 수 있기 때문이다
따라서 우리는 여러개의 Z를 하나의 행렬로 만들어 줄 필요가 있다

가장 간단한 방법은 여러개의 행렬일 이어 붙이고 여기에 새로운 W를 곱해서 하나의 Z를 만들어 내는 것이다
이런식으로 진행되는 것이 multi-headed self-attention이다

지금까지의 과정을 그림으로 정리하면 위의그림과 같다
🔥Positional Encoding
지금까지 진행된 self-attention에는 한가지 생략된 부분이 있다
바로 단어들의 순서이다
문장에서 단어만큼 중요한 것이 단어의 순서이다
따라서 이를 해결하기 위해서 각각의 입력에 positioanl encodeing을 해주어야한다
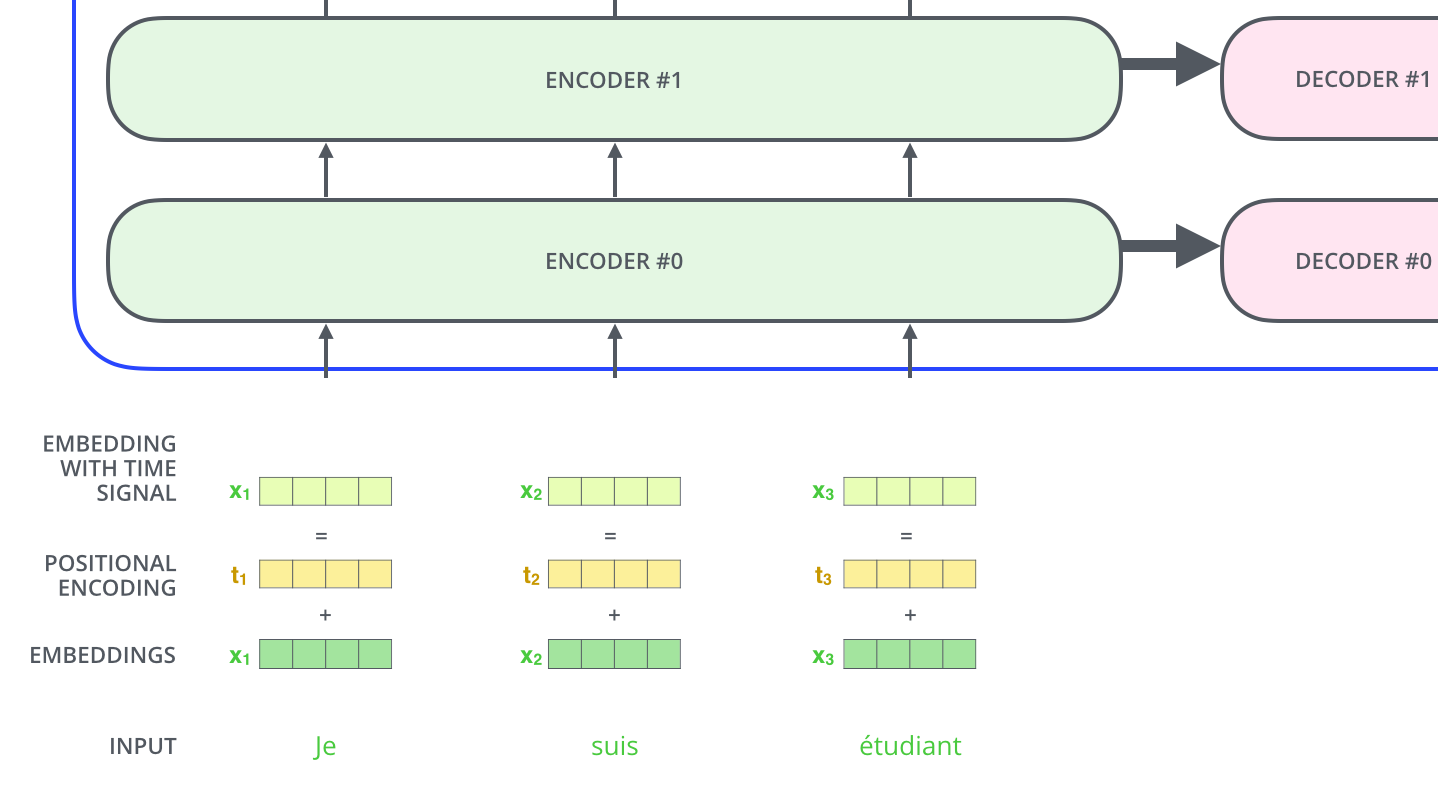
즉, self - attention전에 embeddings input에 positional encoding을 해줌으로써 단어 위치 정보까지 추가해주는 것이다

🔥The Residuals

그리고 Encoder 구조에서 살펴봐야할 구조가 있다
바로 Add & Normalization이다
여기서 Add는 사실상 ResNet의 그것과 같다
그리고 이렇게 Z + X 값을 LayerNorm을 통해서 normalization 해준다
물론 이러한 과정은 Decoder에서도 이루어진다
3. Decoder
위의 Encoder 과정이 끝이나면 Decoder 과정이 시작된다
먼저 Encoder의 최종 attention 벡터들을 K와 V로 변형된다
이제 이 벡터들은 각 decoder의 encder-decoder attention layer에서 decoder가 입력 시퀀스에서 적절한 위치에 집중하도록 도와준다
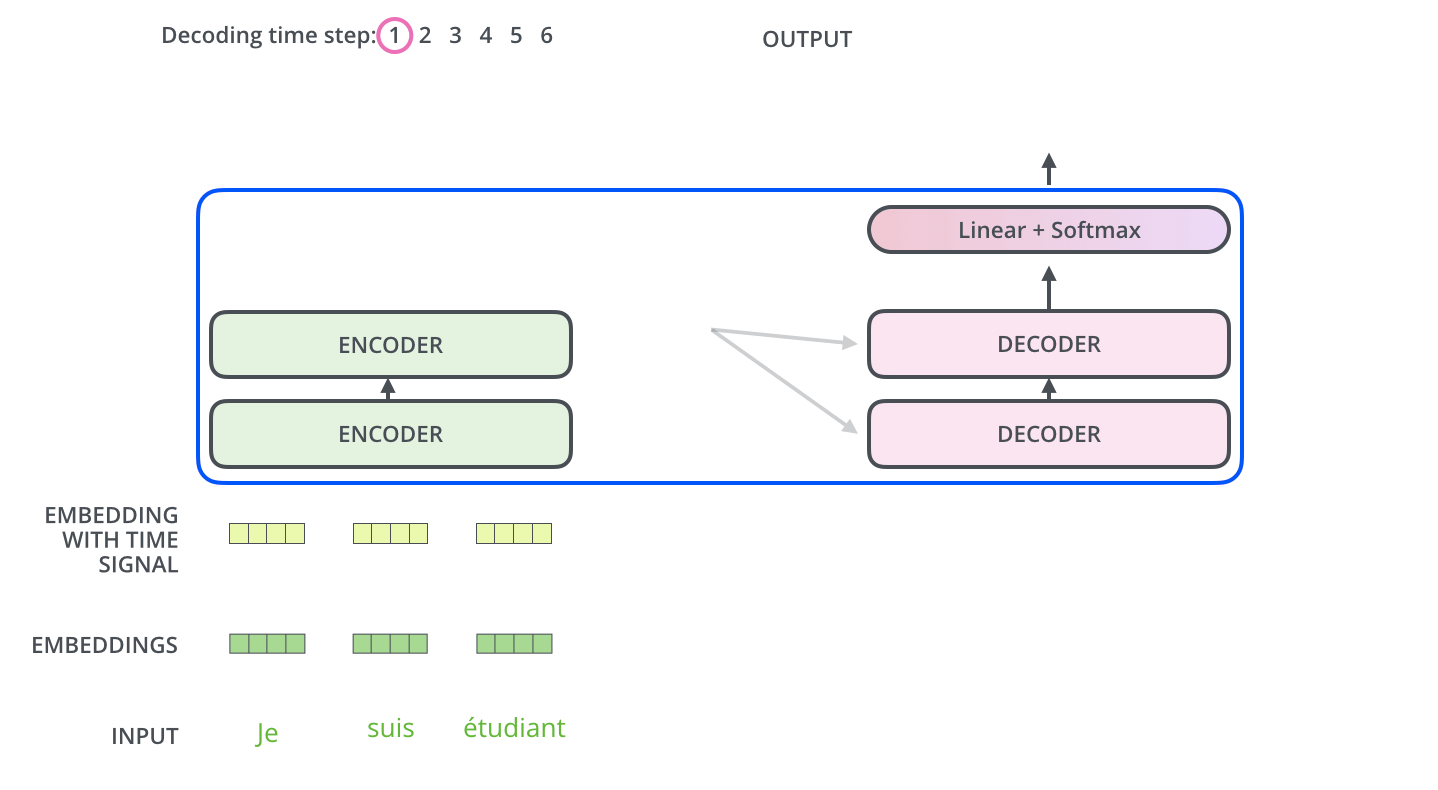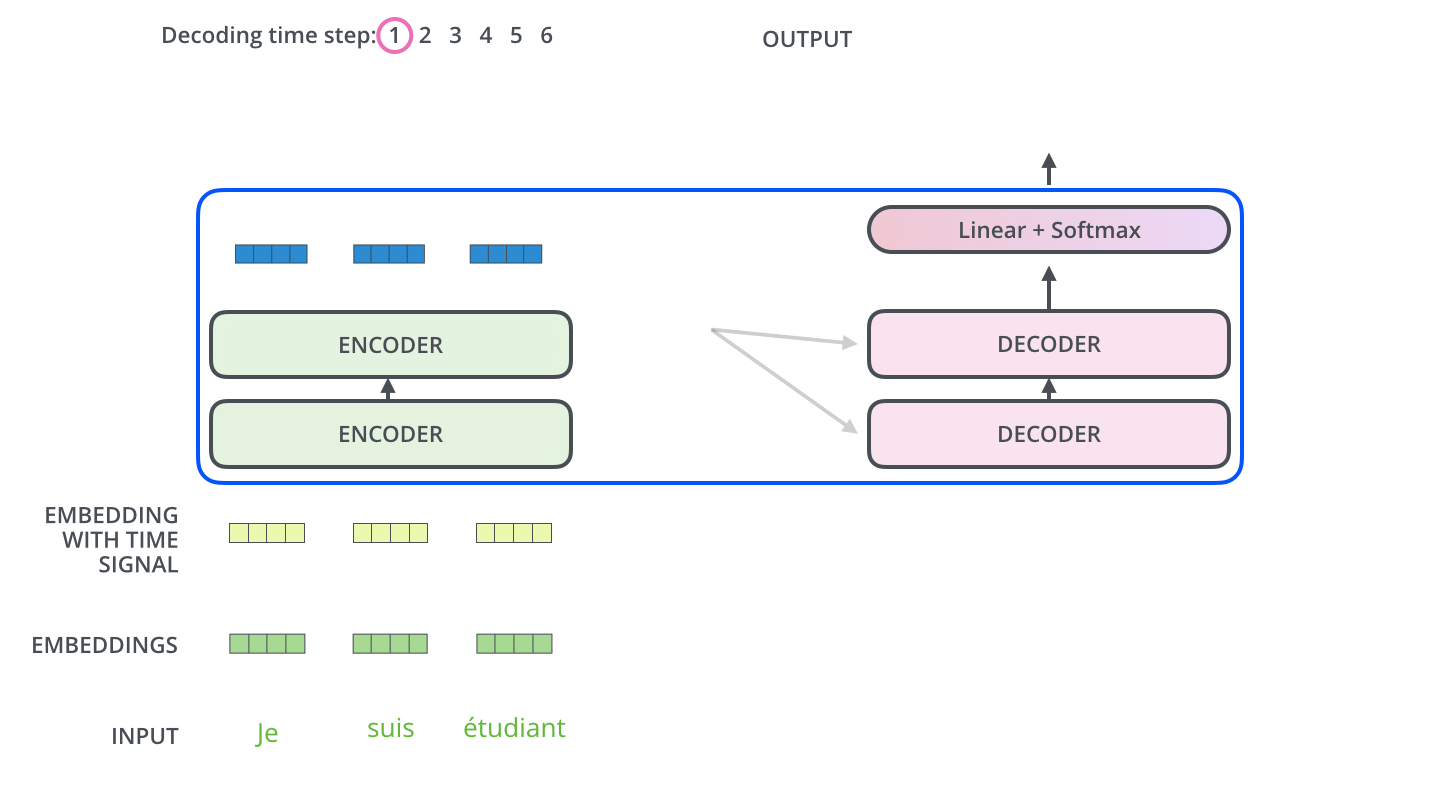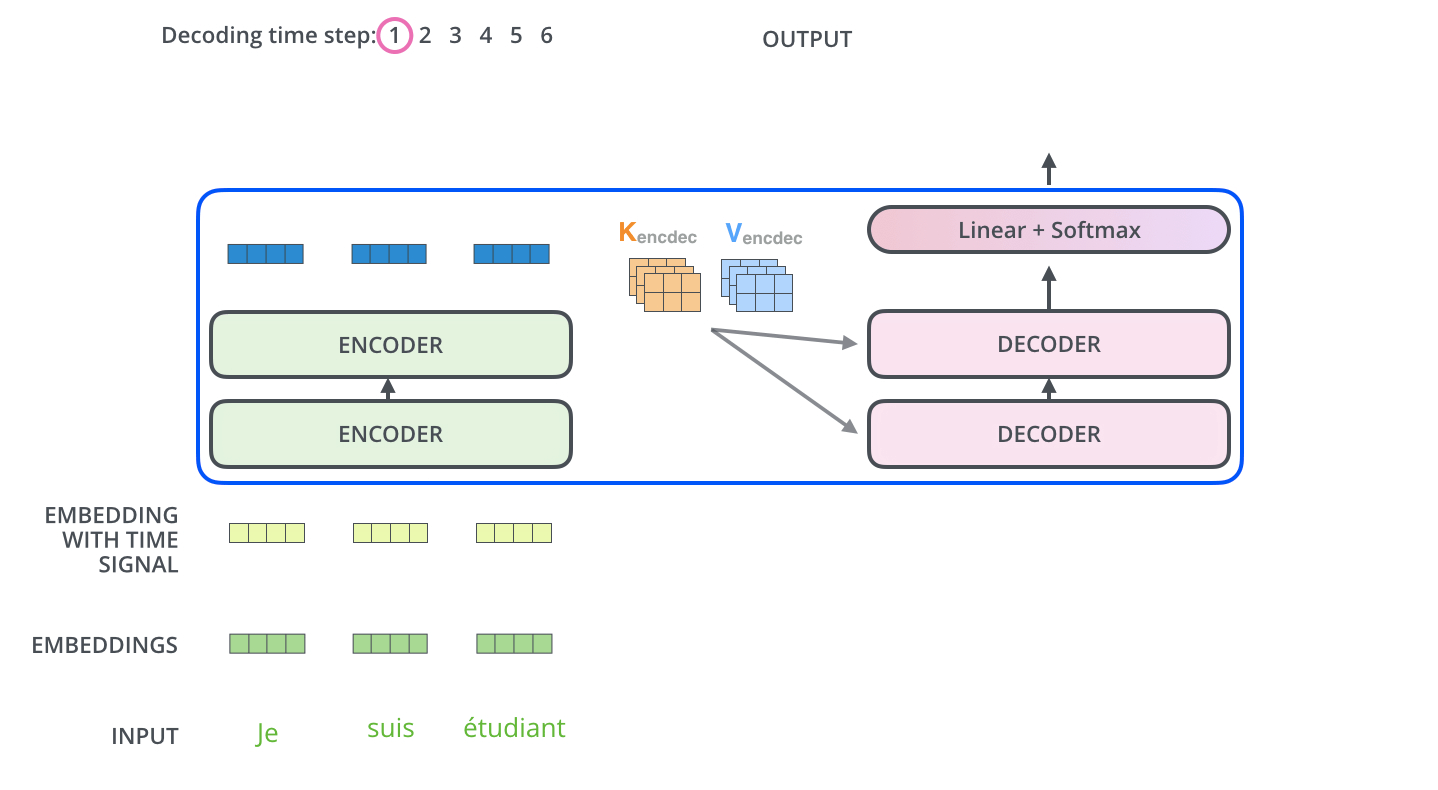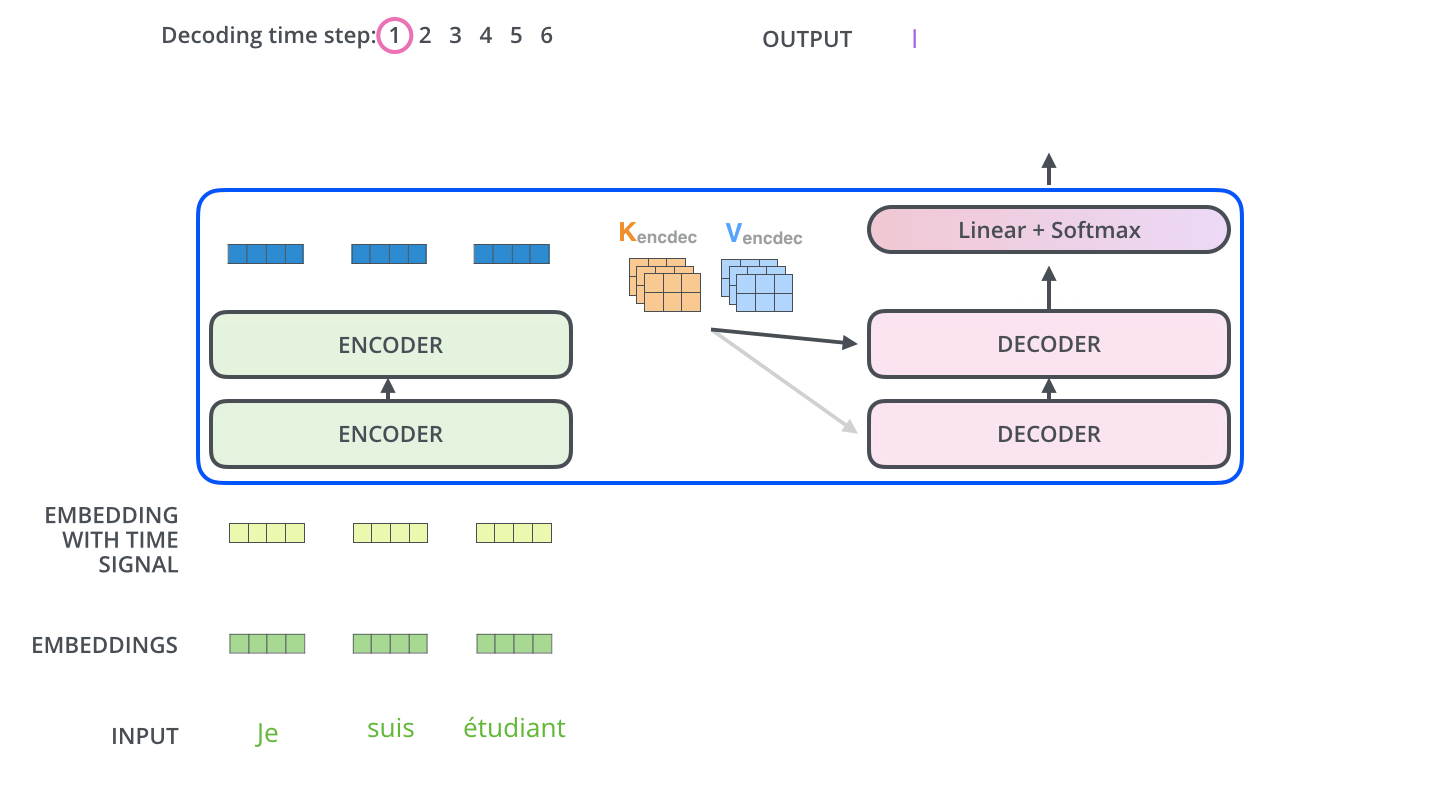
이러한 과정을 거쳐서 시퀀스의 한 단어가 출력되게 되고
끝나는 기호가 나올때 까지 decoding이 반복된다
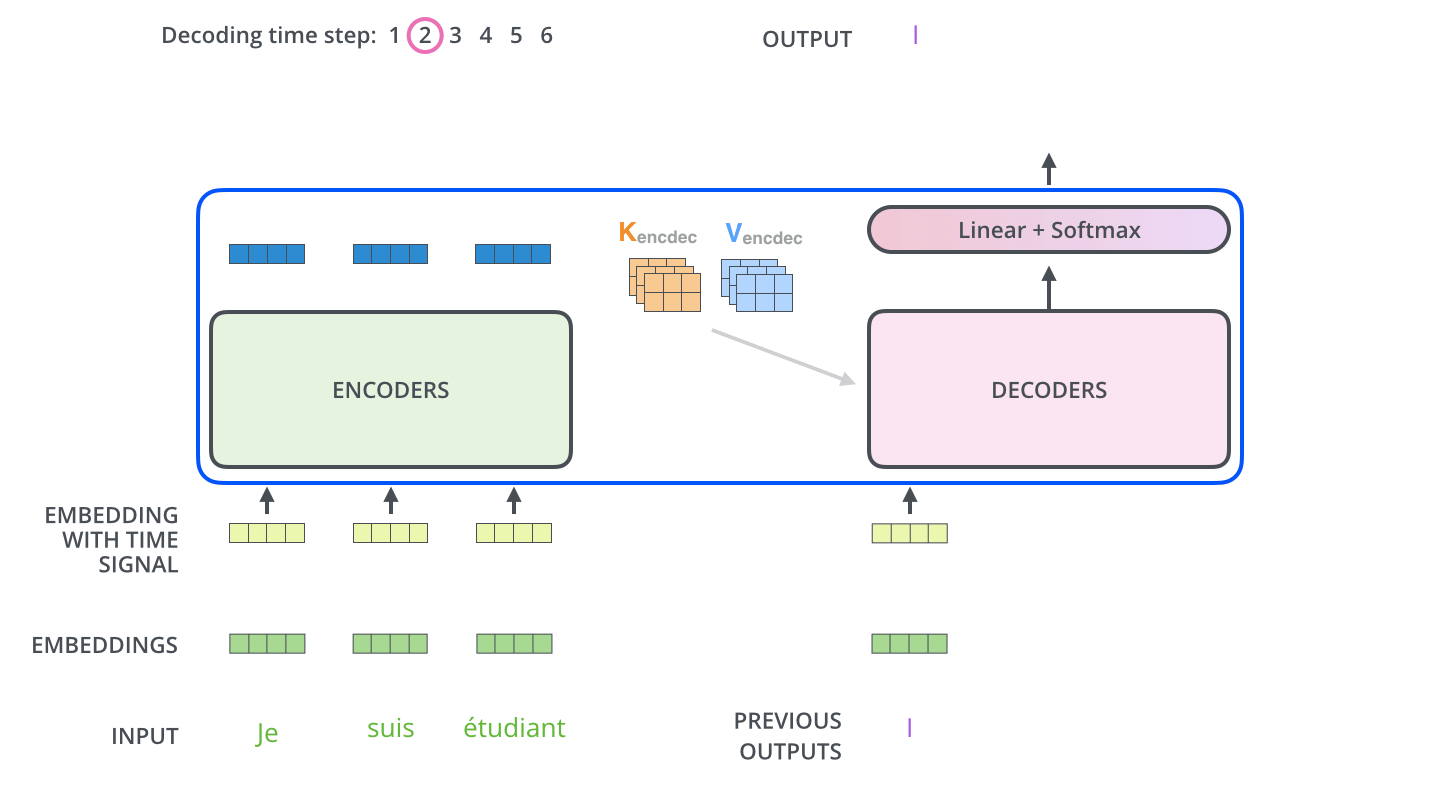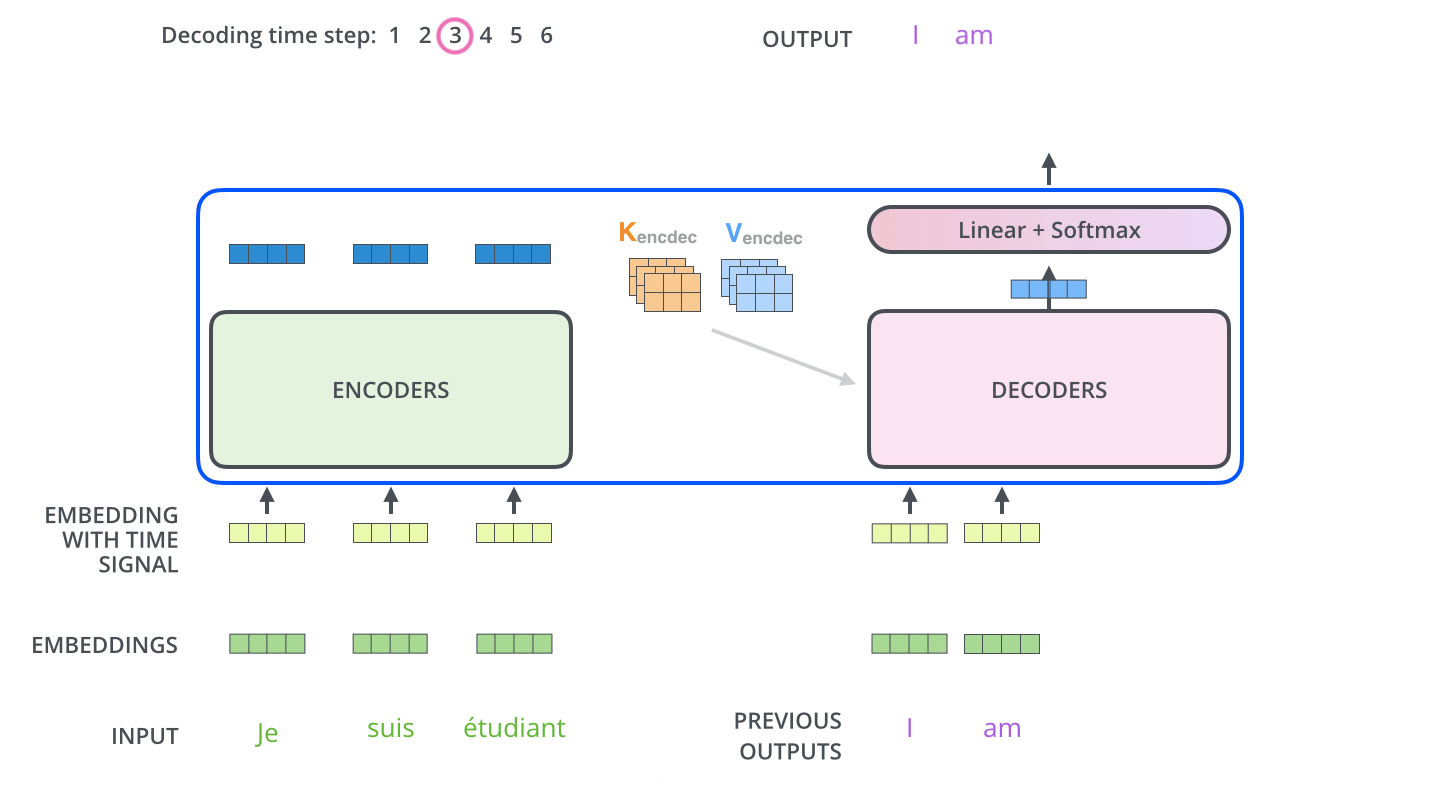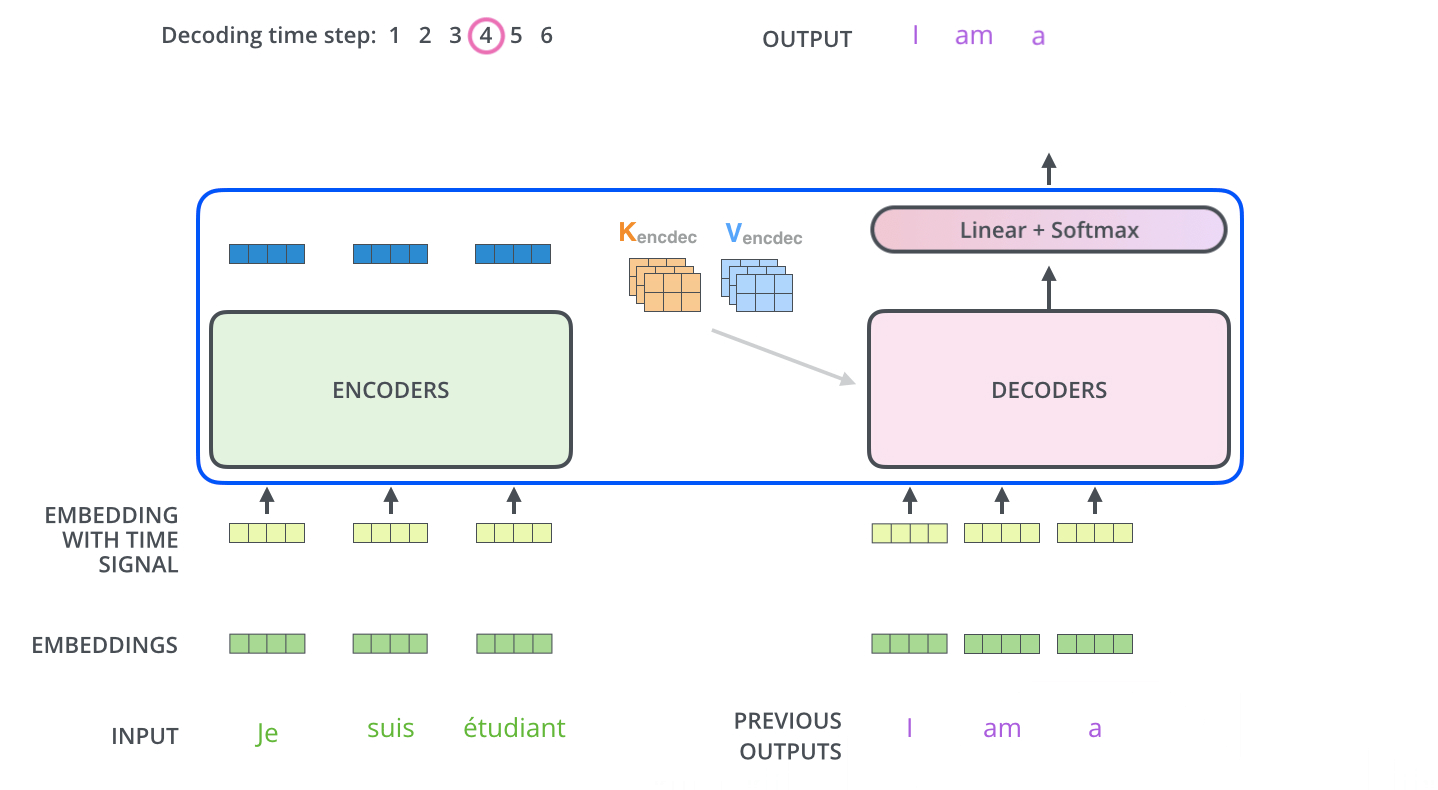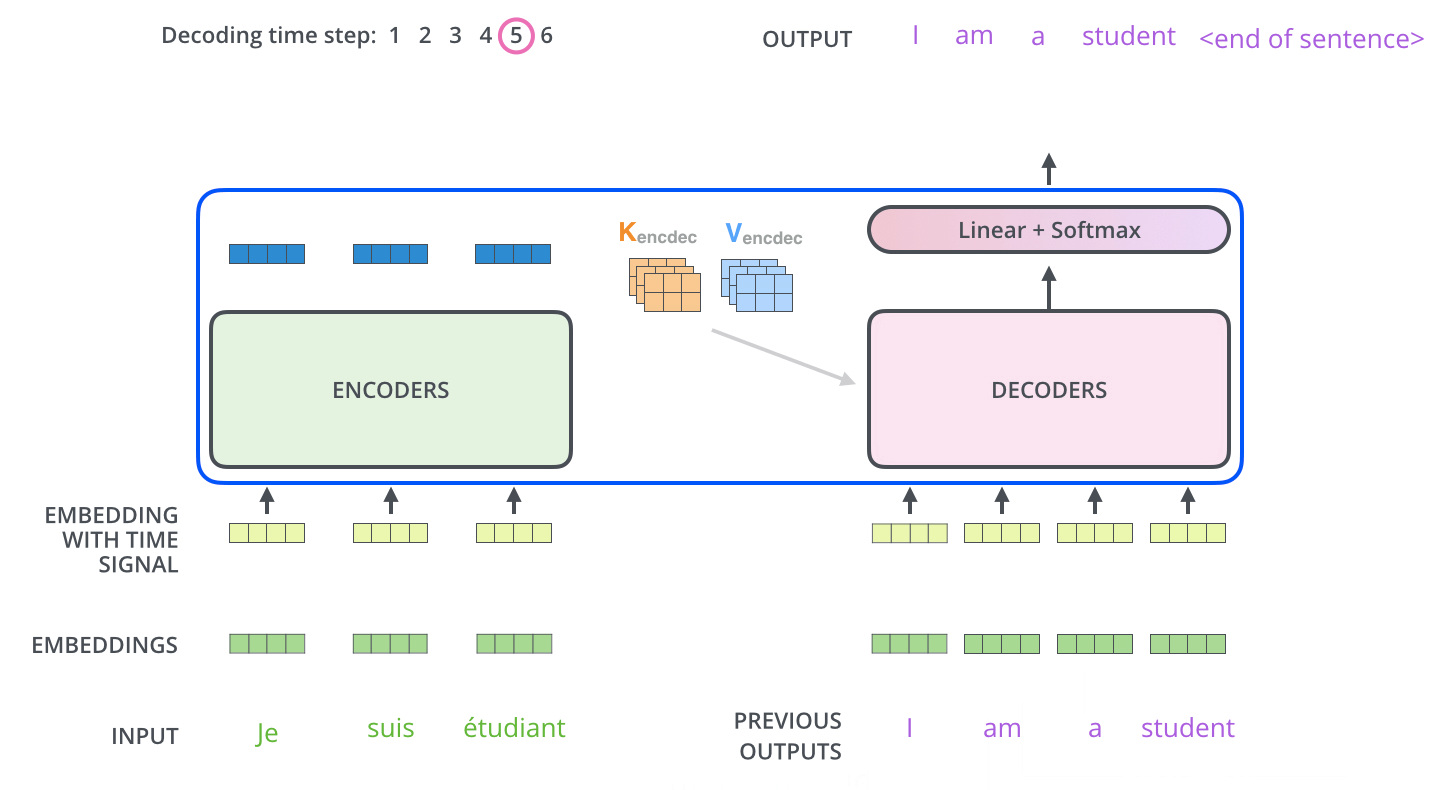
Decoding도 마찬가지로 여러 decoder를 거쳐서 올라가고 positional encoding을 추가해서 각 위치의 정보를 더해준다
🔥Masking
그런데 여기서 decoder의 self-attention은 조금 다른 방법으로 작동한다
앞에서는 모든 단어에 대해서 계산을하고 softmax를 통과 했다면
decoder의 self-attention은 masking이라는 제약을 거는데
이는 현재 위치의 이후 정보들을 지움으로써 -inf로 치환한다 미래 정보를 사용하지 않게 만들어 주는 것이다
🔥Encoder-decoder Attention
그리고 또 다른점은 decoder의 Encoder-Decoder Attention의 경우 Encdoer에서 Key와 Value를 가져오고 Query를 Decoder의 밑의 layer에서 가져온다
결국 여러 decoder를 거치면 소수로 이루어진 벡터 하나가 남게된다
이렇게 남겨진 벡터를 lineary와 softmax를 거치게하면 단어가 나오게 되는 것이고
이를 실제값과 비교하여 오차를 구하고 앞에서 계산에 사용된 가중치들을 업데이트 해주는 과정이 학습과정이다
오늘은 현대 딥러닝 모델의 아니 최신 딥러닝 모델의 근본이라고 할 수 있는 transformer에 대해서 알아보았다
당연히 최.신 기술이기 때문에 복잡할 수밖에 없다
그럼에도 불구 하고
오늘은 큰 산 하나를 넘겼다 ... ⛰️⛰️
하지만 아직 넘어야할 산이 많아 계속해서 성장하는 도비가 되자
'[네이버 부스트캠프] > ⭐주간 학습 정리' 카테고리의 다른 글
[네이버 부스트 캠프 AI Tech] Multi-GPU에 간단한 고찰 (0) 2023.03.24 [네이버 부스트 캠프 AI Tech] Generative Model (0) 2023.03.22 [네이버 부스트 캠프 AI Tech] RNN & LSTM & GRU (0) 2023.03.21 [네이버 부스트 캠프 AI Tech] CNN Models & CNN Task (0) 2023.03.20 [네이버 부스트 캠프 AI Tech] Model Optimizer & Regularization (0) 2023.03.20 다음글이전글이전 글이 없습니다.댓글