- [네이버 부스트 캠프 AI Tech]Multi Modal2023년 04월 05일
- Cat_Code
- 작성자
- 2023.04.05.:28
본 글은 네이버 부스트 캠프 AI Tech 기간동안
개인적으로 배운 내용들을 주단위로 정리한 글입니다
본 글의 내용은 새롭게 알게 된 내용을 중심으로 정리하였고
복습 중요도를 선정해서 정리하였습니다

✅ Week 5
- What is multi modal?
- Visual data & text
1. What is multi modal?

Multi Modal은 무엇일까?
바로 다른 특성을 갖는 데이터들을 함께 이용해서 학습한 모델을 의미한다
우리가 일반적으로 Image나 Text와 같이 각각의 데이터를 활용해서 학습시키는 모델은
Unimodal이라고 한다
하지만 Multi Modal은 text와 image를 함께 활용해서 학습시킬 수 있다
즉, Multi Modal은 쉽게 말해서 사람의 판단처럼 여러 감각 기관들에서 얻은 정보들을 합쳐서 학습하는 것이다
But 이러한 Multi modal은 학습하기가 매우 어렵다
왜냐하면 각 데이터의 유형마다 갖고 있는 정보가 달라서 정보의 양이 Unbalance하고
feature space 또한 다 다르기 때문에 매우 Unbalance하다
따라서 이를 합쳐서 표현할 방법이 필연적이다


이미지와 텍스트 데이터의 표현 방법과 사이즈 등 다른점이 더 많이 존재한다 그러면 간단하게 5:5 비율로 국밥처럼 섞어 먹으면 되지 않을까?
당연히 안된다
모델이 데이터를 인식할 때 데이터의 난이도도 데이터의 유형마다 다를 수 있기 때문이다

이를 해결하기 위해서 다양한 학습 방법들이 제시되었다
다음 부터는 이러한 학습 방법들을 대표적인 task와 model을 살펴보면서 이해 해보도록하자
2. Visual & text data
먼저 살펴볼 내용은 visual data와 text data를 활용한 multi modal task이다
먼저 Text data를 살펴보면
우리가 transformer를 공부하면서 잠깐 언급되었지만
텍스트 그 자체를 모델의 input으로 사용하지 않는다
🔥Word2Vec
먼저 text를 one-hot -encoding 해준다
one-hot-encoding은 쉽게말해서 [0, 1, 0, 0, 0]과 같이 그 단어의 출연 여부를 0과 1로 표현한 것이다
02-08 원-핫 인코딩(One-Hot Encoding)
컴퓨터 또는 기계는 문자보다는 숫자를 더 잘 처리 할 수 있습니다. 이를 위해 자연어 처리에서는 문자를 숫자로 바꾸는 여러가지 기법들이 있습니다. 원-핫 인코딩(One-Hot E…
wikidocs.net
하지만 이러한 방법은 단어들 사이의 관계를 추론하지는 못한다
즉, 단순히 단어의 출연 여부만을 나타낼 뿐이다
그리고 단어의 유사도를 측정할 수 가 없다
따라서 이를 dense vector로 표현해주어야한다
이럴때 사용되는 방법이 word embedding이다
다른 표현으로는 'Word2Vec'이라고 한다
쉽게 말해서 데이터에 등장하는 모든 단어들을 통해서 학습을 한 다음 단어들 사이의 관계를 파악해서
단어를 N개의 차원으로 표현하는 것이다
word2vec | TensorFlow Core
word2vec 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. word2vec은 단일 알고리즘이 아니며 그보다는 대규모 데이터세트에서 단어 임베딩을 학습하는 데 사용
www.tensorflow.org
실제로 사용을 할때는 이미 대규모의 데이터로 pre-trained 되어진 모델을 가져와서 임베딩을 한다
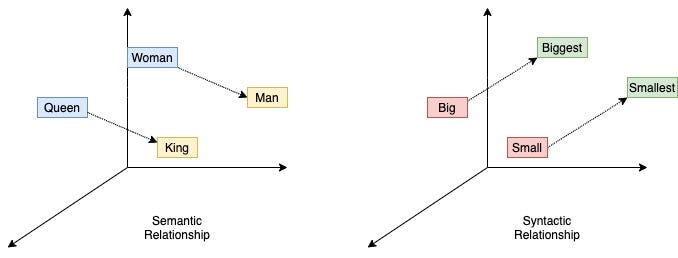
또한 Woman에게 man-king의 차이만큼을 더해주면 Queen이라는 단어가 나온다는 예시처럼
Word2Vec을 활용해서 단어를 차원으로 표현하게 된다면 단어들 사이의 관계를 파악할 수 있다
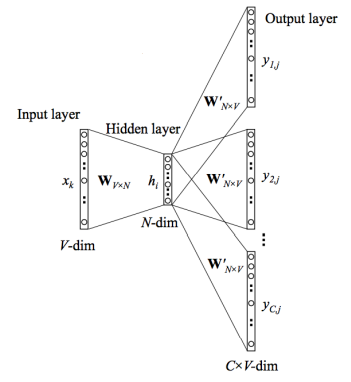
Word2Vec는 아래의 과정을 통해서 학습이 된다
1. one-hot vector에 W가 곱해지면서 특정 row를 embedding
2. output layer에서는 선택된 단어 전후로 어떤 단어가 와야하는지 패턴을 학습
3. 이를 통해서 만들어진 W - hidden layer에 있는, 가 우리가 원하는 vector가 된다

🔥Joint embedding - Matching
이제 text data도 차원을 갖는 vector로 표현이 가능해졌다
따라서 이번에 살펴볼 것은 이런 text data 와 image data를 합치는 방법이다
단순히 합친다고해서 더해주거나 하지 않는다
바로 Word2Vec처럼 Embedding vector를 학습해준다
1. Image tagging
이러한 방법을 활용한 것에 대표적인 예시가 Image tagging이다
쉽게말해서 tag를 보고 이미지를 생성하거나 이미지를 보고 tag를 생성한다

간단하게 pre-trained 되어있는 각각의 모델을 가져와서
하나의 차원에 표현하는데
각각의 모델에서 만들어낸 차원을 갖고 하나의 차원에 표현하여 각 이미지 차원과 텍스트 차원의 유사도를 측정하는 것이다

위의 사진과 같이 유사한 텍스트와 이미지는 가깝게 해주고 관계가 낮은 것들은 거리를 늘려준다
이러한 방식을 활용한 대표적인 모델이 바로
Image&food recipe retrieval이다
image데이터를 받아서 음식 이미지의 레시피와 연결해주는 모델로
Jointembedding방법을 활용해서 학습을 한다

🔥Cross modal translation
하나의 차원으로 표현하는 방법 말고도 각각의 모델을 연결해서 학습하는 방법이있다
이 방법을 Cross modal translation이라고 한다
대표적으로 활용되는 분야가 Image captioning이다
이미지를 input으로 받아서 이미지의 상황을 문장으로 표현하는 task이다

Image captioning의 가장 기본적인 학습 방법은 CNN과 RNN을 연결하는 것이다
즉, Image data의 경우 CNN을 통해서 고정된 feature vector를 추출하고
이렇게 추출한 vector를 RNN의 인풋으로 넣어서 학습하는 방법이다
대표적인 모델이 Show and Tell이다

Show and Tell은 Encoder로 Inception 모델을 활용해서 fixed된 dimensional vector를 형성해 주고
이렇게 fixed 된 vector를 인풋으로 활용해서 RNN 모델에 투입해 문장을 출력하는 구조이다
여기서 조금 더 발전시킨 모델은
Show, attend and tell이다

Review — Show, Attend and Tell: Neural Image Caption Generation
With Attention, Show, Attend and Tell Outperforms Show and Tell
sh-tsang.medium.com
Show and Tell과는 다르게 CNN을 통해서 Features map Vector를 추출하고
이를 바로RNN의 input에 넣는다
그리고 이를 통해서 RNN 모델이 어디를 보고있는지를 Heatmap을 만들어주고 이를 Features map과 결합하여 Z vector를 만들어준다 그리고 RNN의 첫번째 레이어의 아웃풋과 Z를 다시 input으로 넣어서 Heatmap과 output1을 만들고
위 과정을 반복한다
또한 이러한 방법을 Generative Model을 활용한 모델도 있다
Text-to-image 모델로

Text to Image
This article will explain an interesting paper which converts natural language text descriptions to 64x64 RGB images
towardsdatascience.com
- Generator : 텍스트 전체를 고정된 벡터로 만들고 > 가우시안 랜덤코드를 해줘야됨(다양한 아웃풋이 나올수있도록) > 결과도출 (condition + input = C GAN)
- Discriminator : 이미지가 생성된게 들어오면 feature을 뽑고 여기에 문장(얘는 Generator에서 썼던 문장, 즉 컨디서녈)을 합쳐서 true/false 판단 방식으로 학습이 진행된다
🔥Cross modal reasoning
또 다른 방법으로는 두 모델의 feature를 합쳐서 사용하는 방법이다
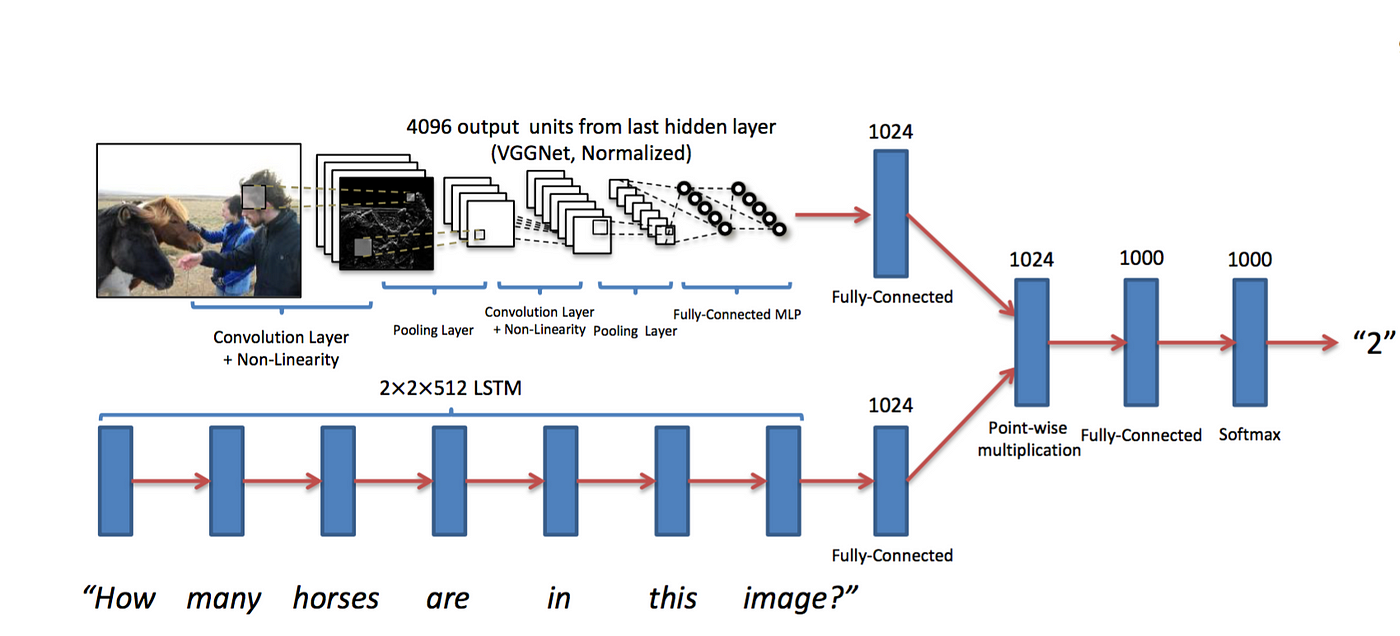
Visual question answering모델은 이러한 방식을 활용한 모델인데
이미지를 보고 질문에 대답하는 모델이다
Python, Machine & Deep Learning
Python, Machine Learning & Deep Learning
greeksharifa.github.io
Deep Learning and Visual Question Answering
Visual Question Answering is a research area about building a computer system to answer questions presented in an image and a natural…
towardsdatascience.com
모델의 구조는 Image stream과 Question stream에서 만들어지는 fixed dimensional vector를 point-wise multiplication하여서 embedding vector가 interaction하게 한다
3. Visual data & Audio
두번째로 살펴볼 multi modal task는 visual과 audio를 함께 활용한 task
🔥Sound representation
Audio 데이터를 학습에 활용하기 위해서는 Spectogram으로 변형을 해주어야한다

이를 위해서 Fourier 변형을 활용하지만 전체 구간이 아니라 짧은 구간 표현이 가능하기 떄문에
STFT를 활용해서 변형을 한다

STFT(Short-Time Fourier Transform)와 Spectrogram의 python구현과 의미
음성신호처리에서 아주 기본적인 feature로 spectrogram이 존재한다. spectrogram을 많이 쓰지만 왜 짧은 시간으로 나눠서 Fourier transform을 하는 지에 대해 생각하지 않고 쓰는 경우가 많다. Python에서 함
sanghyu.tistory.com
이렇게 변환된 데이터를 활용해서 여러 가지 방법에 적용해서 모델을 학습시킨다
🔥Joint embedding - Matching
SoundNet은 Scene recognition by sound task에 사용된다

pre-trained된 모델을 통해 어떤 object에 대한 distribution과 video
장면에서 촬영되고 것에 대한 scene distribution을 출력한다
audio는 raw waveform형태로 CNN input
two heads로 나눠서 각 distribution과 매칭해서 KL loss를 계산한다
spectrogram 대신 waveform을 활용
🔥Cross modal translation
Speech2Face

두번째 모델은 Speech2Face로
음성을 활용해서 그사람의 얼굴을 그리는 모델이다
방법은 Teacher - Student 학습 방법을 활용해서 voice feature가 face feature를 흉내내도록 학습힌다
Face decoder는 학습되어진 모델을 가져와서 활용을하면
face feature을 흉내낸 Voice feature를 Face decoder에 넣어서 이미지를 생성한다
self-supervised learning 방법
Image-to-speech
반대로 image를 넣어서 speech를 생성하는 모델도 있다
image를 input으로 넣어서 CNN을 통해 14 *14의 feature map을 만들고
이를 통해서 Show and tell 모델을 적용하여서 Unit 형태로 출력한다
그리고 이 Unit를 input으로 Speech synthesis에 투입해서 Speech를 형성한다
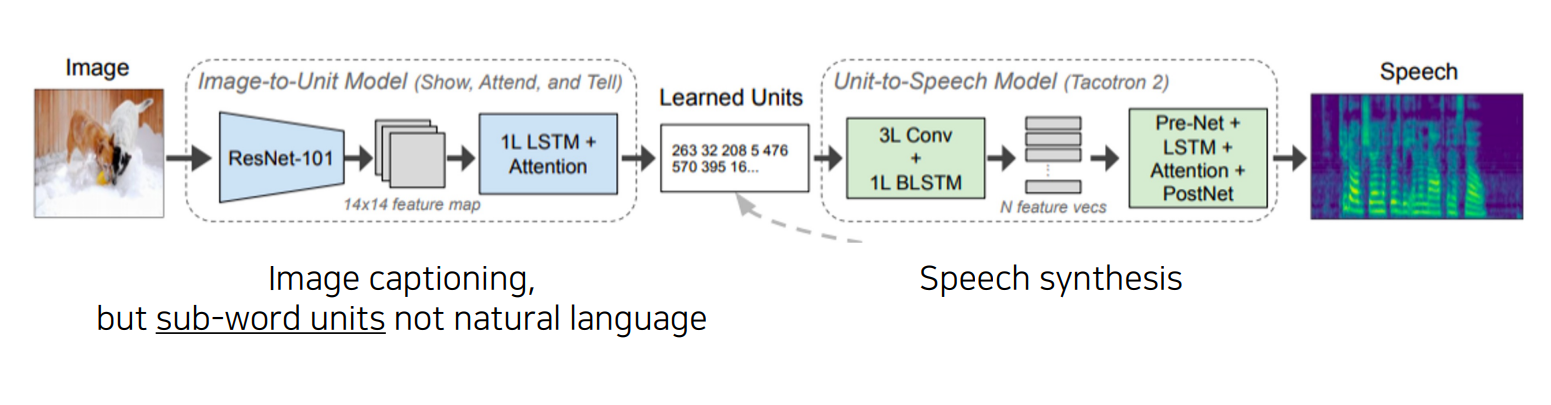
쉽게 말해서 Image Captioning과 Speech Synthesis를 합친 모델이라고 할 수 있다
🔥Cross modal reasoning
Sound source localization
다음으로 살펴볼 방법은 reasoning의 Sound source localization이다
쉽게 표현하자면
영상에서 소리의 위치를 추정하는 task이다

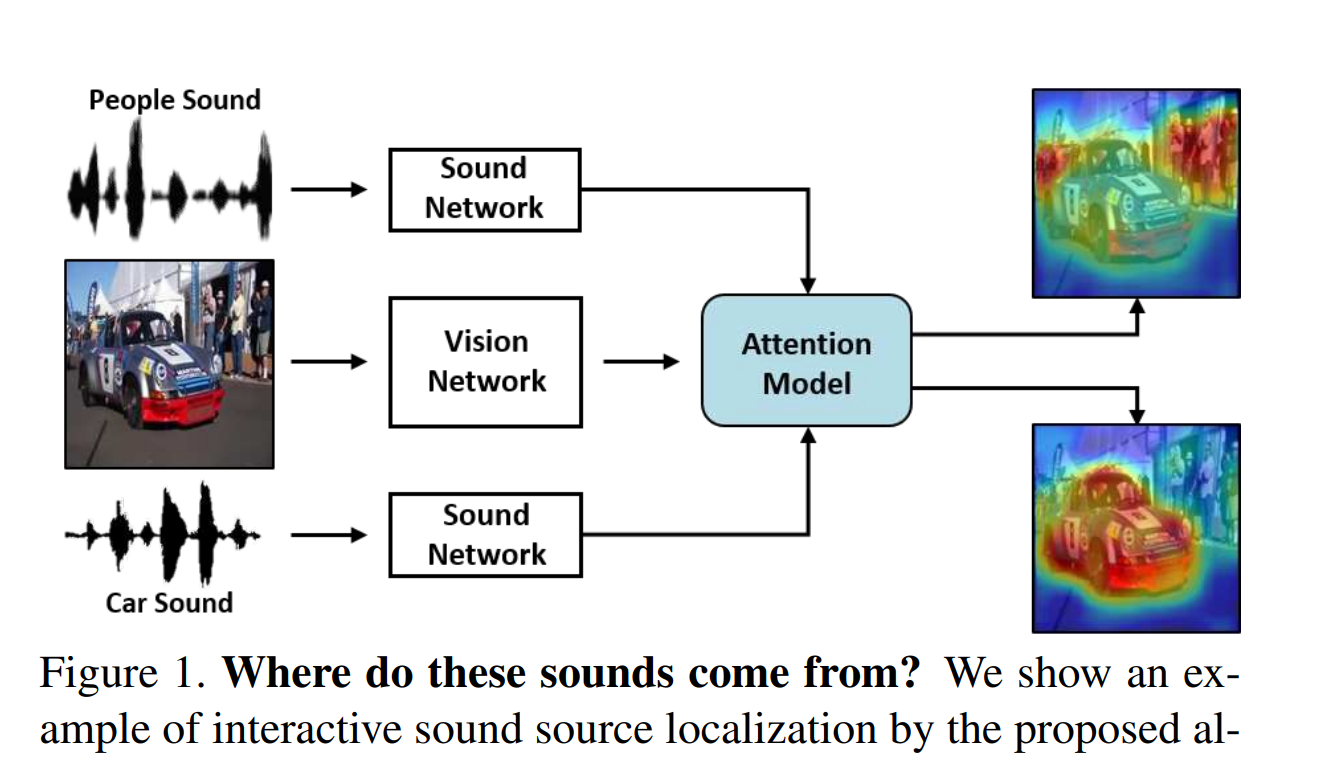
간단하게 설명하면
visual net과 audio net으로 두 부분으로 나누고
각 net을 통과한 feature를 attention model 넣어서 localization score을 만들고
여리게 visual net에서 나온 feature를 곱해서 output을 형성한다
이를 학습하는 방법에서
loss를 계산하는 방법에 따라서
지도학습, 비지도학습, 준지도학습으로 버젼을 나눌 수 있다
Looking to Listen at the Cocktail Party
Looking to Listen at the Cocktail Party: <br/> Audio-Visual Speech Separation
"Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation", Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman and Michael Rubinstein arXiv preprint arXi
looking-to-listen.github.io
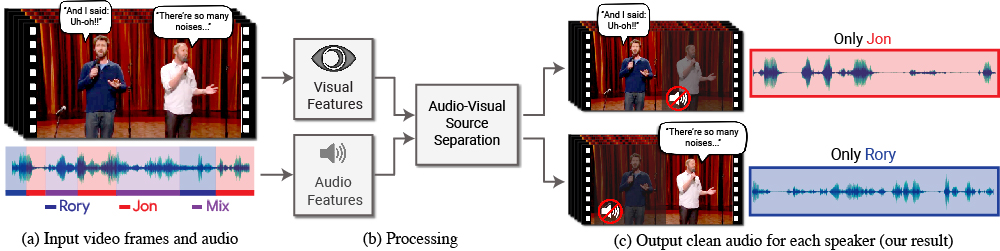
또 다른 task로는 영상에서 나오는 소리의 대상을 선택함에 따라서
조절할 수 있는 task가 있는데
매우 흥미롭다
'[네이버 부스트캠프] > ⭐주간 학습 정리' 카테고리의 다른 글
[부스트 캠프]Week 5 회고 및 Week 6 목표 정리 (0) 2023.04.10 [네이버 부스트 캠프 AI Tech]3D Understanding (0) 2023.04.06 [네이버 부스트 캠프 AI Tech]Conditional Generative Model (0) 2023.04.03 [네이버 부스트 캠프 AI Tech]Landmark Localization & Detecting objects as keypoints (0) 2023.04.03 [네이버 부스트 캠프 AI Tech] Instance & Panoptic Segmentation (0) 2023.04.03 다음글이전글이전 글이 없습니다.댓글