1. 수치 미분과 역전파 | Notion
참고 자료
bottlenose-oak-2e3.notion.site
0. 들어가면서
딥러닝을 공부하다 보면 항상마주치는 개념이 있다.
딥러닝 뉴비들이 갈려나가는 첫번째 위기라고 할 수 있는 오차역전파 (backpropagation) 이다.
고등학교 이후 수학, 특히 미분과 담을 쌓은 사람이라면 또는 수포자였다면 해당 위기는 정말 큰 위기로 느껴질 것이다.
하지만 딥러닝의 핵심을 이해하기 위해서는 (오차역전파라는 개념이 존재했기 때문에 현재의 딥러닝이 가능한 것이다. 최근에는 역전파 이외에 forward-forward라는 방법도 제시되고 있다) 해당 개념을 이해하고 넘어가는 것이 필수 적이다.
이번 시간에는
역전파와 관련된 개념들을 알아보고 numpy를 활용해서 직접 구현해보는 실습 시간을 가져보려고 한다.
학습 목표
- 오차 역전파의 개념과 미분이 딥러닝에서 어떻게 활용되는지 알아본다
- 위 개념들을 활용하여 python과 numpy로 직접 오차 역전파를 구현해본다
고등학생 때 수학을 포기한 자들을 위해서 간단하게 미분 의 개념부터 복습하고 넘어가자.
(미분에 자신있는 사람이라면 넘어가도 상관없다)
미분을 한 문장으로 표현한다면 : 정말 짧은 순간의 변화의 정도이다!!
이는 너무 짧은 순간이기 때문에 한 점에서의 기울기로 보이기도 한다.
1. 미분 (differentiation)
근데 그게 뭐 어쩌라고?

당연히 이런 생각이 드는게 정상적이다. 실제로 우리가 미분 개념을 일상에서 의식하고 사용하지 않기 때문이다.
하지만 미분을 활용한 방법들은 생각보다 우리 주변에 존재한다.
예를 들어서, 자동차를 타고 가는 도로를 상상해보자.
해당 도로 곳곳에 속도 위반 카메라가 존재하는 것을 발견할 수 있을 것이다.
여기서 미분의 개념이 활용되는데, 정말 짧은 순간에 카메라로 자동차를 두 번 찍어서 순간 자동차가 지난간 거리를 계산하여 순간 속력을 측정한다.
이렇듯 시간을 매우 짧게 나눈다고해서 미분 (differentiation) 이라고 부른다.
이제 조금 더 수학적으로 해당 개념을 접근해 보자
아래와 같은 함수의 그래프가 존재한다고 해보자
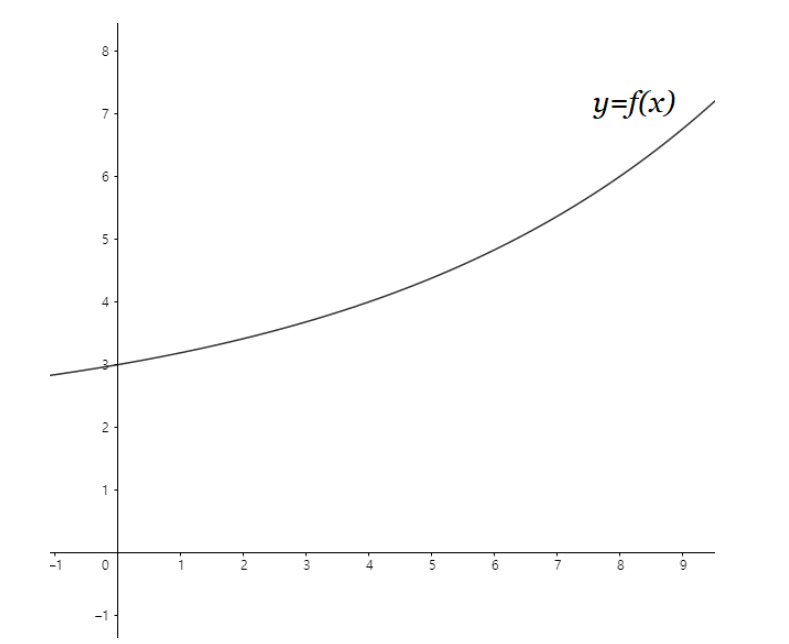
이때, 아래와 같이 구간을 잡아서 변화율 (기울기와 같다) 을 구할 수 있다.
구간을 잡을때, 구간을 0에 가깝게한 기울기를 순간 변화율 이라고하며
구간을 넓게한 기울기를 평균 변화율이라고 한다.
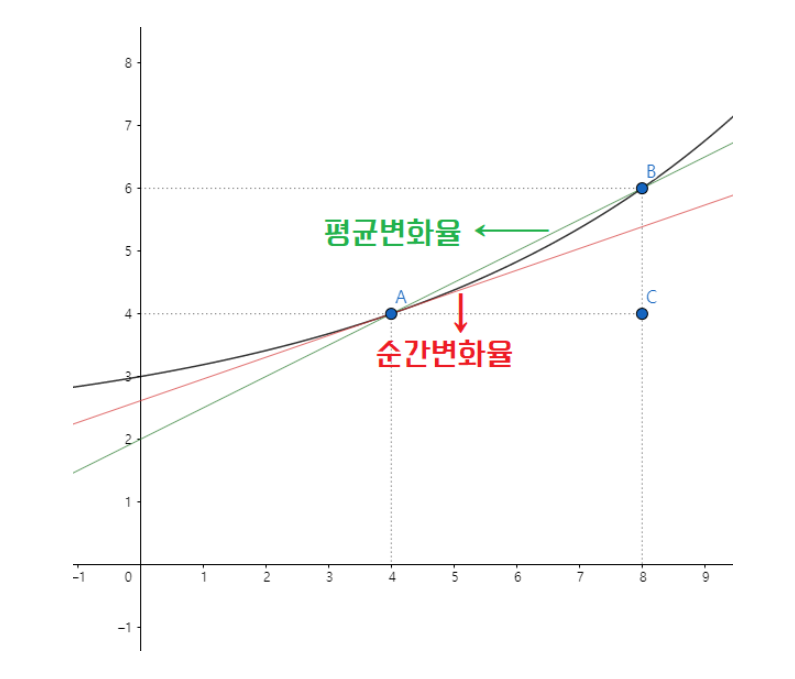
위 그래프에서는 순간 변화율을 x = 4 인 지점에서 계산을 했기 때문에, 해당 함수가 f(x)라고 한다면
f'(4) 라고 표현할 수 있고 이를 프라임 (frime) 이라고도 한다.
이를 일반적인 x에 대한 식으로 일반화한 함수를 도함수라고 하며 f'(x)라고 표현을 한다.
이때 f(x) → f’(x)를 구하는 과정을 오늘 우리가 무조건 알아야할 미분(differentiation) 이라고한다.
쉽게 미분을 정리하자면
주어진 정의역의 모든 x 값에 대하여 순간적인 기울기 (즉, 순간변화율)를 모두 구할 수 있도록 일반화된 도함수를 구하는 것 이라고 할 수 있다.
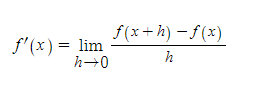
오늘 핵심은 오차 역전파의 개념이기 때문에 도함수를 구하는 방법에 대해서는 생략을 하겠다
대신 관심이 있다면 아래의 링크의 내용을 참고하길 바란다 → (크게 도움이 될 것이다)
도함수를 구하는 방법
[기본개념] 함수방정식에서 도함수 구하기
포스트내용 함수방정식 꼴에서의 도함수를 구하는 방법에 대한 강의입니다. 또 다른 미분과 관련된 강의는 미적분1 은 여기를 누르시고, 미적분2는 여기를 누르세요. 함수방정식에서 도함수 구
bhsmath.tistory.com
2. 수치 미분(Numerical Differential)
미분에는 해석미분(Analytical differential) 과 수치미분(Numerical differential)이 존재한다.
해석 미분 (Analytical differential)
해석미분의 경우 공식을 활용하여 논리적인 전개를 하여 미분을 수행하는 것이다.
하지만 컴퓨터에서 해석미분을 수행하는 것은 매우 한계적이다.
- 해석 미분의 경우 다양한 수학적 식을 해석하고 여러 수학 연산 기호를 사용해야한다. 하지만 컴퓨터의 기호 연산 능력은 한계가 존재하며, 논리적 전개 능력에 한계가 존재한다.
- 또한 컴퓨터가 실수를 표현할때 사용할 수 있는 비트의 수 에는 한계가 존재한다. 이는 식을 전개하면서 반올림 오차(rounding error) 등의 문제를 발생시킬 수 있다.
이러한 단점과 한계점 때문에 컴퓨터에서 미분을 계산할 때 수치미분 (Numerical Differential) 을 활용한다.
수치 미분 (Numerical Differential)
수치 미분은 주어진 함수의 미분 값을 근사화 하기 위해서 구치적인 방법을 사용하는 것이다.
(말이 어렵다…)
쉽게 말해서 아주 작은 차분으로 미분하는 방법으로 미분값을 근사하는 방식이다.
이때 주의할 점은 표현 가능한 비트수에 한계가 있기 때문에 소숫점 8자리 이하로 변화량을 설정하면 안된다.
수치 미분 방식에는 크게 3가지의 방법이 존재한다
1. 전방 차분
전방 차분의 경우 x + h 를 활용하는 방법으로 x의 진짜 미분값과 우리가 근사한 x + h점의 미분값 간에 미세하지만 차이가 존재하게 된다 (h를 근사할 수 있는 부분에는 표현가능한 한계가 존재 하기 때문에 )
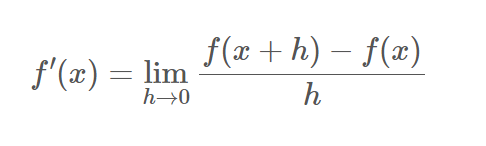
3. 오차역전파 (Backpropagation)
2. 후방 차분
후방 차분 또한 사실 전방 차분을 -로 바꾼 것에 불과하면 전방 차분과 마찬가지로 x - h에 대한 미분 값이기 때문에 진짜 x의 미분과 차이가 발생할 수 밖에 없다.
즉, 위 2개의 방법에는 어느정도의 오차가 발생한다.
이러한 문제점을 보완하기 위해서 사용되는 방법이 바로 중앙 차분이다 .

3. 중앙 차분 or 중심 차분
중앙 차분은 후방 차분과 전방 차분을 결합하여 만들 수 있으며, 위 방법들 보다 x의 진짜 미분 값에 가장 근사 시킬 수 있다.
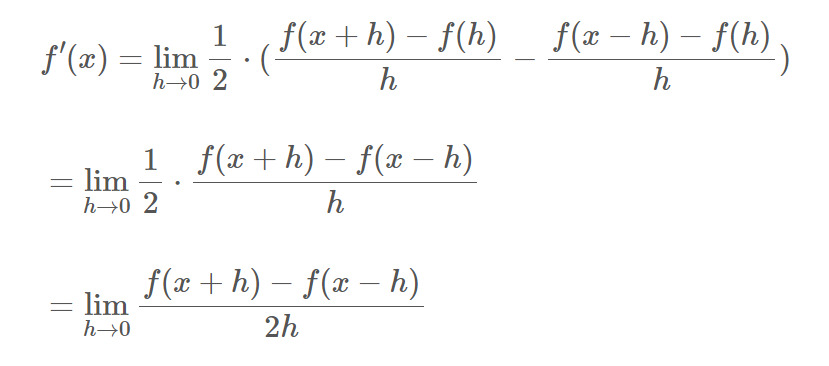
이는 전후방의 차분을 x를 중심으로 계산하는 의미를 가진다.
사실 아래의 증명을 보면 위 차분 모두 수학적으로 같다
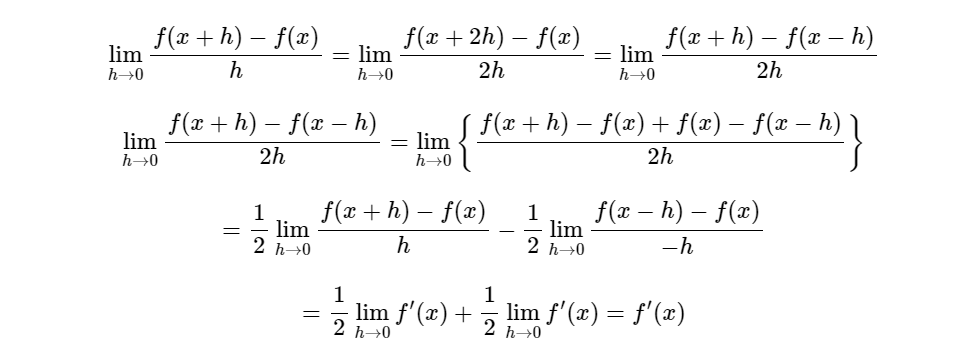
하지만 변화량의 근사값에 따라 약간의 오차가 발생할 수 있는 것이다.
이는 아래의 그래프로도 확인이 가능하다
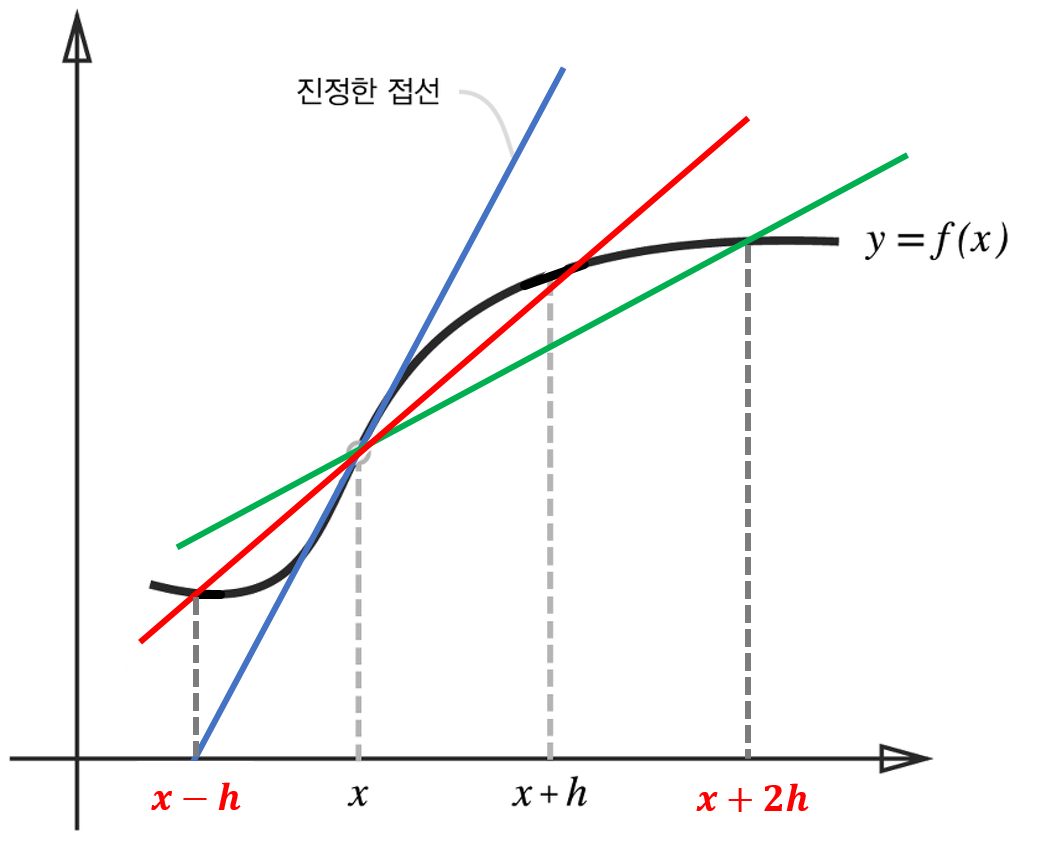
진짜 x의 미분을 파란선이라고 했을때
중앙 차분으로 구한 미분값은 빨간선에 해당하며
x + 2h의 값으로 미분한 값은 초록선에 해당된다.
눈으로 확인할 수 있듯이 중앙 차분을 통해서 구한 값이 전방 또는 후방 차분으로 구한 미분값 보다 실제 미분에 근사하는 것을 확인할 수 있다.
파이썬으로 구현하는 수치미분
# 변화량
dx = 1e-5 ## 주의 할점 언더 플로우가 발생하지 않는 선에서 설정할 것!!
변수가 1개인 함수의 수치미분
import numpy as np
def Simple_numerical_differential(f, x, dx):
return (f(x + dx) - f(x -dx) / (2 * dx))
## 확인 ##
def f(x): # x^2
return x ** 2
ret_val = Simple_numerical_differential(f, 3.0)
print(ret_val)
// 6.000000000039306 //
편미분 (변수가 여러개!!)
def derivative(f, x, dx):
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = tmp_val + dx
fx1 = f(x)
x[idx] = tmp_val - dx
fx2 = f(x)
grad[idx] = (fx1 - fx2) / (2 * dx)
x[idx] = tmp_val
it.iternext()
return grad
def f2(W):
x, y = W
return (x ** 2 + x * y + y ** 2)
ret_val = derivative(f2, np.array([1.0, 2.0]))
print(ret_val)
//해석//
1. x와 같은 크기의 영행렬(grad)을 생성합니다.
2. np.nditer 함수를 사용하여 x를 순회하는 이터레이터를 생성합니다.
이터레이터는 각 원소에 대한 인덱스를 제공합니다.
3. 이터레이터를 사용하여 반복문을 돌며 각 원소의 인덱스(idx)를 가져옵니다.
4. 현재 원소의 값을 tmp_val에 저장합니다.
5. 현재 원소의 값을 dx만큼 증가시키고, 이를 통해 함수 f를 호출하여 그 값을 fx1에 저장합니다.
6. 현재 원소의 값을 dx만큼 감소시키고, 이를 통해 함수 f를 호출하여 그 값을 fx2에 저장합니다.
(5,6번 은 중앙 차분을 위해)
7. 중심 차분을 사용하여 해당 원소에 대한 미분값을 계산하고, 이를 grad에 저장합니다.
8. 현재 원소의 값을 다시 이전 값으로 되돌린 후, 다음 원소로 이동합니다.
9. 모든 원소에 대한 미분값을 계산한 후, 그 값을 반환합니다.
이때, 우리는 수치 미분의 명확한 단점을 확인 할 수 있다.
변수가 1개일 떄는 크게 문제가 보이지 않았지만!! 변수가 여러개로 증가했을 때
계산량이 증가한다는 것이다.
즉, 편미분을 수행할 때, 변수마다 다른 변수를 상수로 취급하고 각각의 연산을 수행해야하기 때문에 변수의 수가 증가함에 따라 계산량도 증가하게 된다.
이는 변수의 수가 엄청나게 증가할 수 있는 딥러닝 모델에서는 매우 치명적인 단점이 된다.
(계산량도 증가하기 때문에)
이러한 단점을 해결하기 위해서 딥러닝에서 활용하는 방법이 바로 오차역전파 (Backpropagation)이다.
3. 오차역전파 (Backpropagation)
여담으로 사실 딥러닝의 개념은 최근에 등장한 개념이 아니다.
실제로 1958년에 퍼셉트론이 발표되었다. (무려 약 70년 전…)
하지만 1969년 단순한 퍼셉트론은 XOR 문제를 해결할 수 없다는 사실을 Marvin Minsky 교수가 증명하였고 다층 퍼셉트론을 통해서 해결할 수 있으나
해당 다층 퍼셉트론을 학습시킬 방법이 없다는 이유로 (수치미분으로는 엄청난 계산량이 발생하였기 때문에) MLP를 학습시키는 방법은 존재하지 않는다고 여겨졌고, 퍼셉트론의 신화는 정말 신화처럼 여겨졌다.
하지만 시간이 흐르고 1974년 하버드 대학교의 박사과정이었던, Paul Werbos라는 사람이 MLP를 학습시킬 수 있는 방법이 존재한다고 주장하였고 이를 Marvin Minsky 교수에게 설명하지만,
일개의 박사과정의 주장을 진지하게 받아주는 사람은 없었다.
그렇게 그의 주장이 조용이 묻혀 가던중 1986년 David E. Rumelhart, Geoffrey E. Hinton**(이분은 forward - forward 알고리즘을 주장하기도 함 → 딥러닝의 아버지)**, Ronald J. Williams 등의 논문에서 해당 개념을 다시 사용하게 되었고 이후 MLP를 학습시킬 수 있는 알고리즘이 실제로 존재한다는 것이 받아들여 지기 시작했으며 이후 MLP의 시대를 시작하게 만든다.
그렇게 Paul Werbos가 주장한 방법이 바로 오차 역전파 (Backpropagation)이다.
오차 역전파의 등장
왜? 오차역전파가 등장하기 이전에, 단순한 퍼셉트론은 학습이 가능했는데 MLP는 학습이 불가능했을까?

위 사진처럼 단순하게 하나의 층또는 2개 정도의 레이어로 구성된 perceptron의 경우 수치 미분을 통해서 (시간은 걸리겠지만) 계산이 가능하다.
하지만 해당 모델이 깊어지면 깊어지고 layer가 더 많이 쌓일 수록 계산해야하는 양은 기하급수적 (또는 그이상) 증가하게 된다.
따라서 현대 컴퓨팅 환경에서는 사실상 무한대에 가까운 시간일 걸릴 것이다.
이러한 수치미분의 한계 때문에 오차 역전파가 등장하기 이전에는 MLP의 학습이 불가능했던 것이다.
극소점 계산
MLP에서 오차 역전파를 살펴보기전에

위와 같은 계산 식이 있다고 가정해보자
이때, 슈퍼에서 1개에 100인 사과를 2개 사고, 소비세가 10%부가된다고 한다면

위 와같은 그래프로 표현해볼 수 있다. (당연히 매우 간단한 식이기 때문에 계산은 어렵지 않다)
그렇다면 이번에 1개에 100원인 사과 2개, 1개에 150원인 귤 3개를 샀다면 ? (물론 소비세 10% 부과)

앞에 보다는 조금 복잡하지만 그래도 계산은 문제가 없다.
그렇다면 슈퍼에서 사과 2개를 비롯해서 여러 식품을 구입했다고 생각해보자
이때 여러 식품의 총합은 4000원이다.
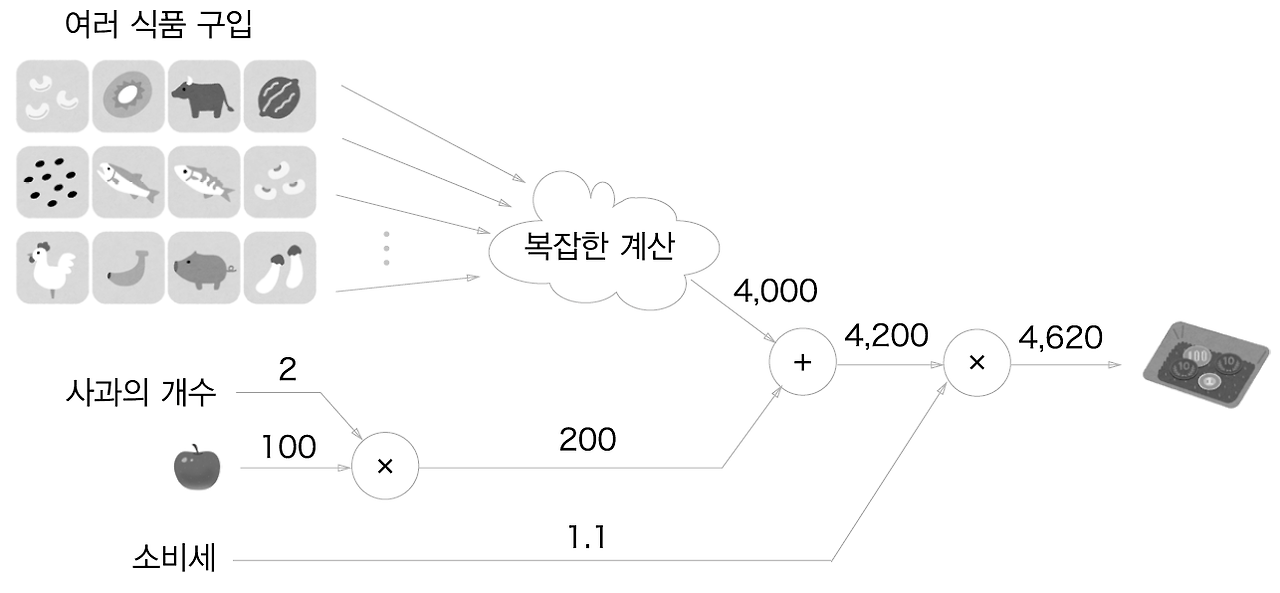
그렇다면 위와 같은 계산 그래프를 통해서 표현할 수 있다.
자꾸 왜 계산그래프를 등장시키는지 의문일 것이다.
눈치가 빠른 사람이라면 알수 있을 것이지만
계산 그래프의 장점은 바로 국소점 계산 에 있다.
국소점 계산이란 전체에 어떤 일이 벌어지든 상관없이 자신과 관계된 정보 만으로 결과를 출력하는 것을 의미한다.
즉, 위 계산식에서 사과와 여러식품의 가격이 합쳐져 4200원이 되는 계산은 여러 식품이 어떠한 식으로 계산되었든지 상관없이 사과값과 해당 계산식의 결과인 4000원을 더하기만하면된다.
즉, 아무리 복잡한 식이라도 계산 그래프의 장점은 각 노드에서 단순한 계산에 집중을 할 수 있다는 것이다. 이러한 원리는 역전파를 이용해 미분을 계산할 때 매우 효율적이다
가장 간단했던 사과 계산 그래프로 예시를 들어보자
사과 가격에 대한 지불 금액의 미분 값 계산 그래프에 대한 역전파는 아래와 같이 표현할 수 있다.
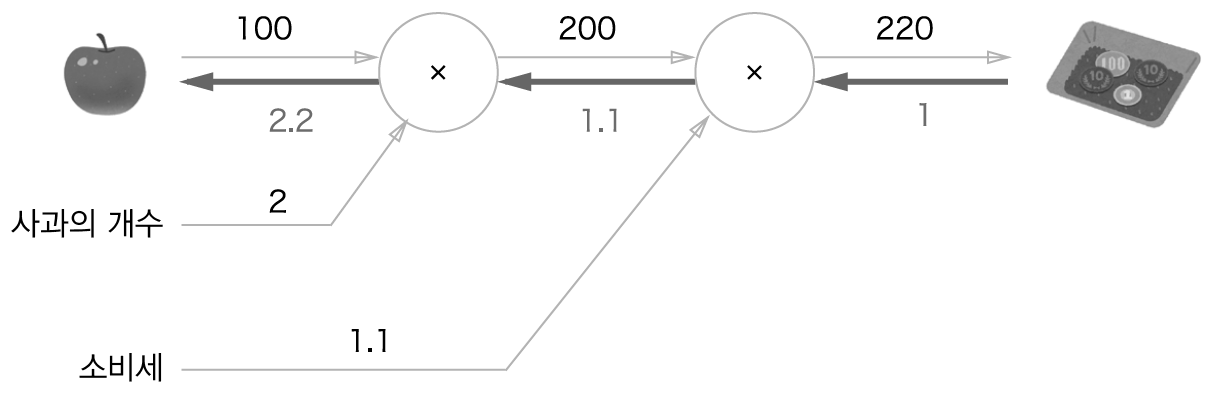
순전파 (사과로 부터 출발해 비용 계산을 하는 방향)과 반대인 역전파는 굵은 선으로 표시되었다.
이때 역전파는 국소적 미분을 전달하고 그 미분값은 화살표 아래에 적었다.
해당 예시에서 역전파는 오른쪽에서 왼쪽으로 1-> 1.1 -> 2.2 순으로 전달된다.
따라서 지불 금액의 미분값은 2.2 라고 할 수 있다.
즉, 사과가 1원 오르면 금액은 2.2원 오르게 된다.
연쇄법칙 (Chain Rule)
위 계산은 역전파에 의해서 수행되었다.
이때, 오차역전파의 근간을 이루는 원리는 국소적인 미분을 전달할 수 있게 만들어 주는 연쇄법칙 (chain rule)이다. (그먼씹…)
즉 y = f(x)라는 함수의 역전파를 표현해보면
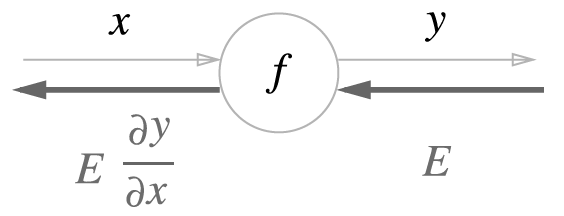
으로 나타낼 수 있다. 즉, 역전파의 계산은 E 노드의 국소적 미분인 (변화량 y/ 변화량 x)를 곱한 후 다음 노드에 전달 되는 것이다.
이는 합성함수를 미분할때 활용되는 방법이다. 어려운 수학이지만 예시를 보면서 이해해보자
$$ z = (x + y )^2 $$
라는 함수가 있다고 가정해보자
이때
$$ t = (x + y) $$
로 가정을 할 수 있다.
따라서 z를 x로 미분하였을 때
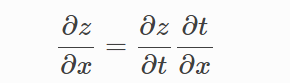
아래의 연쇄법칙이 성립된다.
이말은 z를 x로 미분한 것은 (z를 t로 미분한것) x (t를 x로 미분한것)과 같다는 것을 의미한다.
즉, z를 x로 미분 = (2t) * (1) 0= 2(x + y)가 된다. (이는 합성함수 미분 공식과 같다)
이렇듯 합성함수를 미분할때 사용할 수 있는 법칙이 연쇄 법칙이다.
이번 글에서는 연쇄법칙의 증명을 다루지는 않을 것이다.
관심있는 사람이라면 아래의 링크를 참조하길 바란다.
8. 연쇄 법칙과 증명 (Chain Rule)
7. 미분 공식 (Differentiation Formulas) 에서 함수의 합에 대한 미분법칙, 곱에 대한 미분법칙, 차에 대한 미분법칙 등등 함수들의 대수적인 연산에 대한 미분법칙에 대해 알아보았었다. 이번 포스팅에
vegatrash.tistory.com
그래서 연쇄법칙이 뭐 어쨌다고 오차역전파를 가능하게 만들까?
우리가 알고있는 MLP는 사실 하나의 함수로 볼 수 있으며 해당 함수는 여러 다변수 함수의 합성함수로도 볼 수 있다.
따라서 수치미분이 MLP에서 불가능했던 이유는 해당 합성함수들 처럼 변수의 수가 증가했기때문에
계산량이 증가했기 때문이다.
하지만 방금 배원 연쇄 법칙 을 이용한다면
복잡한 다변수에 대한 미분을 하나의 식으로 표현할 수 있다.

위에서 살펴본 예제를 계산그래프에 적용해서 연쇄법칙을 살펴보자
$$ z = (x + y )^2 $$

역전파의 맨 왼쪽에 나타나는 값은 x에 대한 z의 미분이라는 것을 확인할 수 있다.
쉽게 말해서
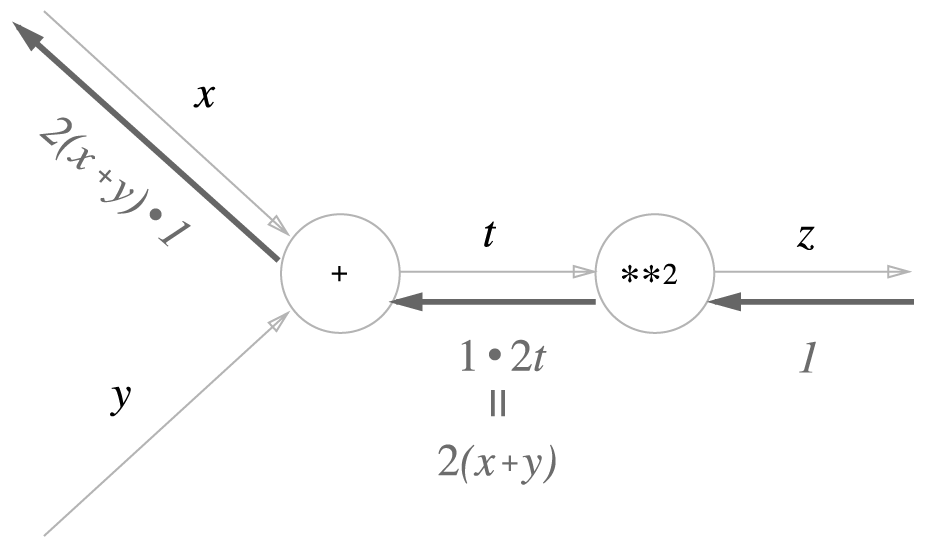
위와 같은 식으로 치환 해서 볼 수 도 있다.
또다시 역전파
이제 우리는 역전파의 큰 근간인 연쇄법칙에 대해서 알게 되었다
그렇다면 실제로 역전파를 계산해보자
(물론 pytorch나 라이브러리를 사용할 때, 역전파를 손으로 계산하는 미친짓은 하지 않을 것이지만 우리의 목표가 이해이고 구현이기 때문에 간단한 예시로 계산해보는 것은 무해하다. - 우리 뇌에는 유해할 수 있지만…)
덧셈 노드 (or 뺄셈 노드)
덧셈에 대한 역전파의 경우 다음과 같다
(예시는 계속 같은 예시로 하고 있다!!!)
z를 x로 미분했을때 = 1, z를 y로 미분했을 때 = 1 이기 때문에
아래의 그래프로 표현할 수 있다.
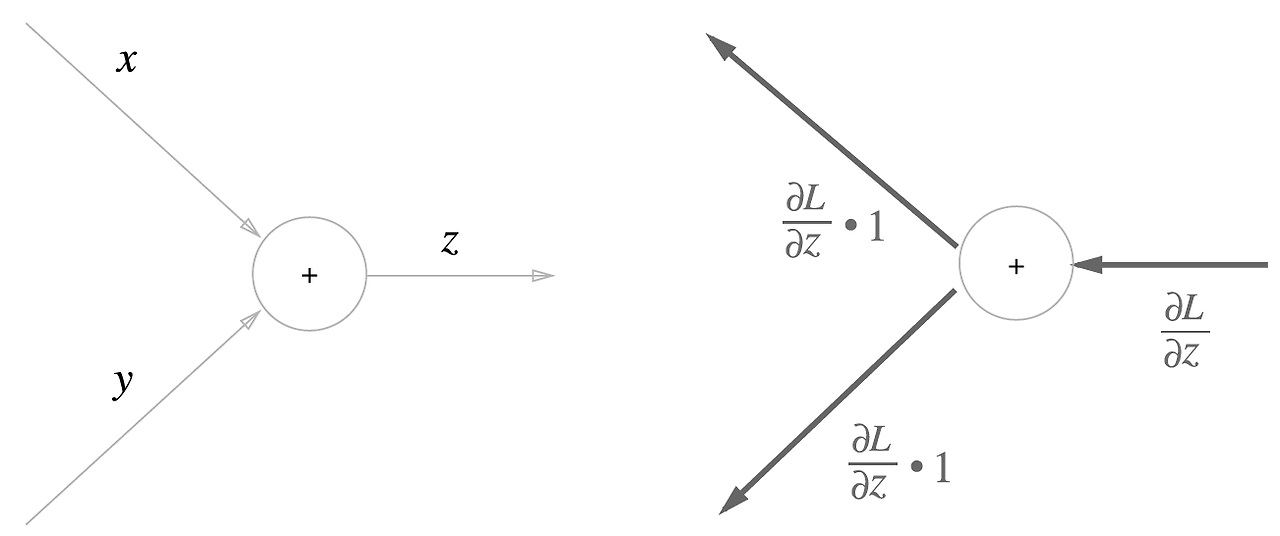
구체적으로 10 + 5 = 15라는 수식으로 변환 해본다면 아래와 같다
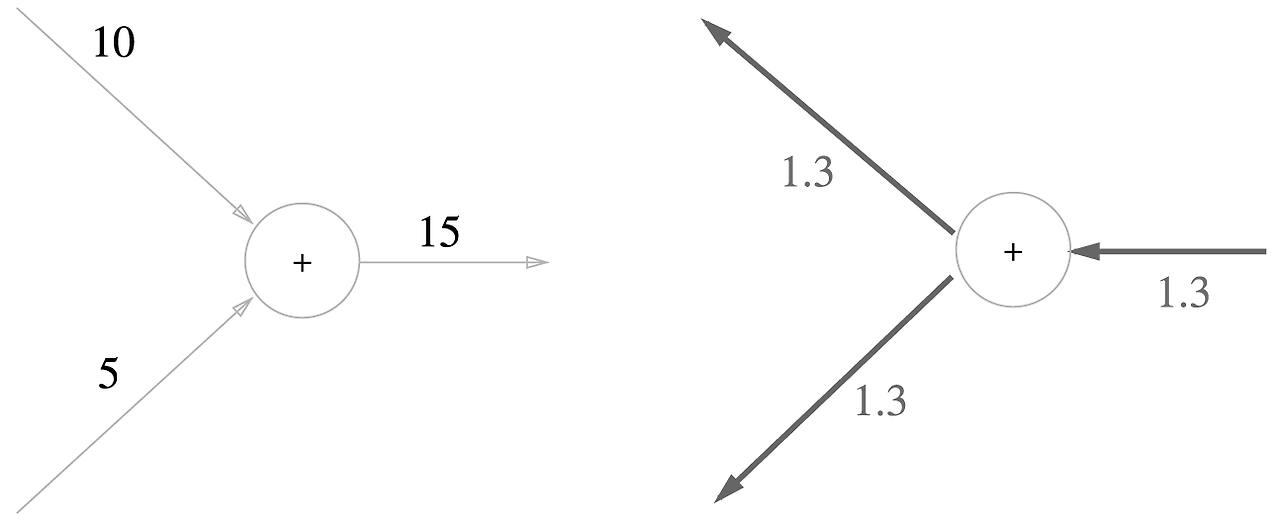
쉽게 말해서 아무런 영향이 없다. 즉, 덧셈 노드 역전파는 입력 신호를 다음 노드로 출력할 뿐이다.
(it same = -)
곱셈노드 (or 나눗셈 노드)
z = xy라는 식에서 역전파를 생각해보자
z를 x로 미분하면 = y, z를 y로 미분하면 = x가 된다
즉, 아래와 같은 그래프로 표현할 수 있다.

이를 10 x 5 = 50이라는 계산 식에 적용했을때 (이때 위의 임이의 식에서 넘어온 미분은 1.3이다)
아래의 그래프로 표현할 수 있다
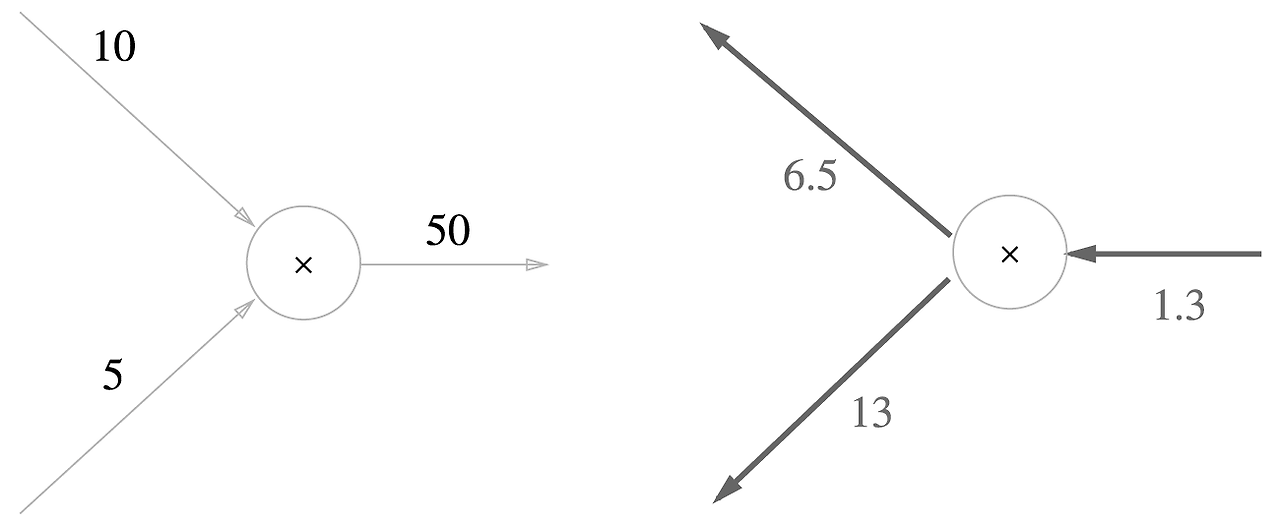
즉, 곱셈의 역전파를 정리하면 상류의 값에 순전파 때의 입력 신호들을 서로 바꾼 값을 아래로 흘려보낸다.
y 에는 1.3 x 10이 x에는 5 x 13이 전달 되고 있다.
따라서 곱셈의 역전파는 순전파의 입력 신호값이 필요하다. 따라서 곱셈 노드를 구현할때는 순전파의 입력 신호를 변수에 저장해두어야한다. (그래서 역전파때 GPU의 메모리를 많이 잡아 먹는 것이다 → 노드의 순전파 입력신호를 모두 저장해두기 때문에)
지금까지 계산 그래프에 대한 역전파를 살펴보았다.
사실 MLP의 미분도 위 계산 그래프와 다르지 않다. 대신에 다양한 연산이 추가되고, 순전파에서 계산되는 결과값이 Loss (오차)로 바뀌고, 층이 조금더 깊게 쌓일 뿐이다.
근간이 되는 연쇄법칙을 생각한다면 결국 하나의 곱셈형태의 식으로 이루어진다.
실제 MLP의 경우에는 다양한 활성화 함수 (activation function) 로도 이루어져 있다
나중에 기회가 되면 정리하겠지만
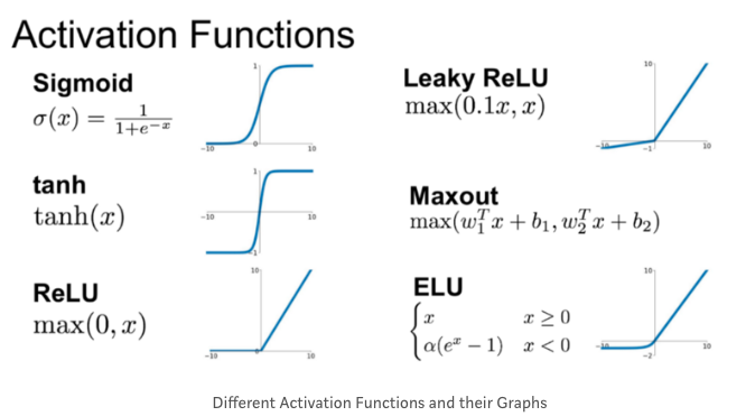
이와 같은 미분가능한 활성화 함수들이 있다.
이러한 활성화 함수도 미분이 가능하기 때문에 역전파를 계산할때에는 미분 식을 적용해서 하위 노드의 미분값을 전달 해줄 수 있다 (참고 하라고- 지금 생각하면 복잡스만 해짐)

대충 예시를 그래프로 표현하면

그래서 뭐?
그래서 이렇게 구한 미분 값은 어떻게 사용될까?
사실 MLP에서 역전파는 실제 y과 예측 y’에 대한 Loss에 적용이된다.
즉, Loss (오차)를 적게 만드는 방향으로 가중치(weight)들을 조절해 나가는 것이다.
쉽게말해서 역전파로 구한 미분 값 은 가중치 업데이트에 적용이 된다.
보통은 경사하강법 을 통해서 가중치를 업데이트 한다.

즉, 사용자가 지정해준 학습률 (learning rate)에 오차를 w로 편미분한 값을 곱해서 이전 가중치에 빼줌으로 조절을 하는 것이다. (오차가 적거나 학습률이 적으면 당연히 가중치에 조절이 적게 가해진다)
나중에 자연스럽게 알게 되겠지만 학습률을 무지성으로 높게 잡으면 모델이 학습 되지 않는 이유가 여기에 있는 것이다
'ML 🐼 > 딥러닝 🔫' 카테고리의 다른 글
| MIM의 Masking 방법들 (0) | 2024.07.21 |
|---|---|
| [논문리뷰] Masked Autoencoders Are Scalable Vision Learners(MAE) (0) | 2024.07.01 |
| [논문 리뷰] Notion 논문리뷰 링크 (0) | 2023.08.31 |
| [논문 리뷰] CutMix : Regularization Strategy to Train Strong Classifiers with Localizable Features (2) | 2023.03.05 |
| [딥러닝]활성화 함수 (Activation) (0) | 2023.01.11 |