1989년 'Backpropagation applied to handwritten zip code recognition, LeCun, 1989'을 시작으로 CNN의 이론적 토대가 완성되었다. 이는 1998년 'LeNet'으로 연결 되었으나 당시의 하드웨어적인 한계 때문에 큰 모델을 사용하기 힘들었다. 그런 중 2012년 LeNet을 발전시킨 AlexNet이 나오게 되고 GPU를 사용한 모델 학습이 가능해짐으로써 본격적인 CNN의 시대가 개막하게 되었다.
✅본격적인 시작에 앞서서 간단히 살펴 보는 CNN
- 많고 많은 신경망 모델 가운데 왜? 이미지는 CNN인가?
CNN을 사용하기 이전에도 MLP(다층 신경망)를 사용하여 이미지를 학습할 수 있었다. 그러나 이는 이미지를 flat하게 풀어서 사용하였기 때문에 이미지의 공간적 정보를 잃게 되며 학습적 능률에서도 떨어지게 된다. 반면에 CNN을 사용하게 되면 공간적 정보를 살릴 수 있고 바로 연산을 하기 때문에 학습 시간도 줄일 수 있다.
- 합성곱 신경망은 어떻게 작동하는가?
나중에 시간이 되면 간단하게 소개할려고 합니다.
간단한 이해를 원한다면 아래 블로그를 참고하길 (CNN에 대해서 깔끔하게 정리된 글)
[딥러닝 CNN] 1. CNN이란?
CNN 기초정리 원래는 mnist 데이터를 다루려고 했는데, 그래도 CNN 기초정리는 해야겠어서 잠깐 살짝 다루고 넘어가겠습니다. 0. 시작 전에 CNN에 대해서 깊게 설명하려면 일단 기존 DNN의 개념부터
youngq.tistory.com
🏳️🌈논문 Review
논문 : https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
Abstract
AlexNet은 이미지 분류 경연 대회인 ImageNet LSVRC-2010의 이미지 데이터(1000개의 클래스를 가진 120만 장의 고해상도 이미지 데이터 셋)를 학습하여 top-1 error는 37.5%, top-5 error는 17.0%로 지난 모델 중 가장 높은 성능을 얻어냈다 (2012년 논문인 점을 감안하길 바란다)
- top-1, top-5 error란? : [개, 고양이, 호랑이, 집, 사람, 자동차]이라는 클래스로 학습된 모델이 있다고 가정하고 test 데이터를 입력했다고 가정하면 이 모델은 아마도 0.1, 0.6, 0.05, 0.05, 0.02, 0.03으로 분류할 수 있을 것이다. 여기서 고양이로 예측한 확률이 가장 높기 때문에 (0.6) top-1 class는 고양이가 된다. 그리고 top-5 class는 높은 순서대로 [고양이, 개, 호랑이, 집, 자동차]가 된다. 만약 여기서 top-1 class가 실제 클래스와 일치한다면 top-1 error는 0%이고 top-5 class중 실제 클래스가 포함되어 있다면 top-5 error는 0%가된다. 여담으로 1000개의 클래스로 훈련된 분류기에서 top-5 error가 5%보다 낮다면 상당히 좋은 분류기라고 할 수 있다.
이 모델은 6천만개의 파라미터와 65만개의 뉴런, Max-pooling이 포함된 5개의 합성곱 레이어와 3개의 fully-connected 레이어로 구성되어 있으며 마지막에는 1000개의 클래스로 분류해주는 softmax 함수가 연결 되어있다. 또한 과적합을 방지하기 위해서 dropout을 활용하였고 ILSVRC-2012대회에 참가하여 1위를 수상했는데 top-5 error가 15.3%로 26.2%를 기록한 2위 모델을 크게 앞지르는 성능을 보여주었다.

2개의 GPU를 병렬 연산하였기 때문에 병렬구조로 설계되어 있다.
Introduction
최근 객체탐지를 위해서 많은 머신러닝의 기법들이 활용되고 있으며 많은 데이터셋, 강력한 모델, 과적합을 피하기위한 기법들이 필요하다. 기존 작은 데이터셋 (MNIST)은 기존 방식을 통해서 높으 성능을 낼 수 있다. 하지만 현실에서는 변동성이 다양하기 때문에 더 많은 양의 데이터 셋을 활용한 학습이 필요하며 실제로 LabelMe, ImageNet과 같이 많은 양의 데이터 셋을 이용할 수 있게 되었다. 또한 GPU가 강력해지면서 CNN 이미지 학습이 가능해졌다.
또한 수천개의 객체와 수십만개의 이미지를 학습하기 위해서 더큰 학습 능력이 필요하며 엄청난 복잡성을 해결해야한다. 하지만 이를 위해서 방대한양의 데이터 셋만은 부족하며 이미 가진 데이터 뿐만 아니라 우리가 없는 데이터를 적용하기 위해서는 모델에 대한 방대한 사전 지식또한 갖고 있어야한다. 이를 위한 모델이 바로 CNN 모델이다.
CNN모델은 깊이와 너비를 변화시킴으로 모델의 크기를 조절 할 수 있고 이미지를 더 잘 예측할 수 있다. 또한 , stationarity of statistics와 locality of pixel dependencies라는 CNN의 특징 덕분에 일반적인 Feedforward Neural Network(순방향 신경망)보다 더적은 연산량을 갖게 되고 훈련하기가 쉽다 (비슷한 성능을 내면서)
stationarity of statistics와 locality of pixel dependencies :
Stationarity는 이미지의 한 부분에 대한 통계가 어떤 다른 부분들과 동일하다는 가정이며 이는 이미지의 특징이 위치에 상관없이 다수 존재할 수 있으며 다른 위치에서 학습한 특징을 활용해 동일한 특징을 추출할 수 있다는 의미
Locality of pixel dependencies는 이미지가 작은 특징들로 구성되어 있기 때문에 픽셀의 종속성은 특징이 있는 자은 지역에 한정된다는 것 즉, 이미지를 구성하는 특징은 일부 지역에 근접한 픽셀들로만 구성되고 근접한 픽셀들끼리만 종속성을 가진다는 것
하지만 CNN을 학습하기 위해서는 엄청난 비용이 필요하다. 이러한 문제는 GPU의 발달로 가능하게 되었다.
- 논문에서 사용된 GPU 환경 : GTX 580 3GB 2개 (당시에는 역대급 스펙)
The Dataset
- ImageNet 데이터셋 활용 : 22000 카테고리에 대한 1500만 개의 이미지를 제공함 또한 ILSVRC(이미지 분류 경진대회)에서 사용하는 Test Data를 활용해서 모델을 평가함
- Alex Net은 256x256 픽셀의 고정된 크기의 input값을 받기 때문에 이미지를 resize하고 downscale해주었다. How? : 짧은 부분이 256이 되도록 rescale하여 중앙을 256x256사이즈에 맞추어 잘라냈다. 또한 각 픽셀에서 전체 픽셀의 평균을 빼주어 zero-centered(값이 실수 전체에서 나타나는 것)를 맞추어 주었다.
The Architecture
(1) ReLU
(현재 ReLU를 활성화 함수로 많이 사용하고 있지만 논문이 쓰여지던 당시에는 tanh과 sigmoid가 주로 사용됨)
AlexNet에서는 많은 양의 데이터와 깊은 네트워크 구조 때문에 빠르게 학습할 능력이 요구된다. 이를 위해서 ReLU 활성화 함수를 사용하였는데 tanh과 비교했을 때 6배 정도 빠른 시간을 보였다.
물론 ReLU는 본 논문이 처음 제안하는 것이 아니다. 이전 연구에서는 과적합을 피하기 위해서 ReLU를 활용했다(Jarrett et al) 그러나 AlexNet에서 주요 목표는 과적합 방지가 아니라 빠른 학습이다.

(2) Training on Multiple GPUs
더 많은 연산능력을 위해서 3GB GPU를 2개를 활용하여 (병렬로) 사용하였다.
병렬방법은 커널(뉴런)의 절반만큼 각각의 GPU가 각각 담당하는 것이다. 그리고 특정한 layer에서만 GPU가 서로 상호 작용한다. 이런 특정 layer가 2번 layer라면 3번 layer에서는 2번 layer의 모든 feature map을 입력 받는다. 그리고 다시 4번에서는 할당된 부분만 입력 받는다. 이는 top-1 error와 top-5 error를 각각 1.7, 1.2% 줄였으며 속도도 향상하였다.
[이러한 방법은 columnar CNN과 비슷하다- 구조가 비슷하다는 이야기]
(3) Local Response Normalization
ReLU는 saturationg을 예방하기 위해서 정규화를 할 필요가 없다는 특성을 갖고 있다 (매우 좋다)
그러나 지역 정규화 방법(Local Response Normalization)이 일반화를 돕는 다는 사실은 여전히 발견되었다.
[쉽게 말해서 ReLU를 사용하기 때문에 정규화가 필요없지만 Local Response Normalization을 사용하면 장점이 있기 때문에 사용했다] -> 한 뉴런의 값이 너무 커지면 주변의 다른 뉴런에 영향을 줄 수 있기 때문에 측면억제(lateral inhibition)
*** 하지만 현재는 Local Response Normalization은 잘 사용되지 않고 Batch Normalizaion이 주로 사용된다
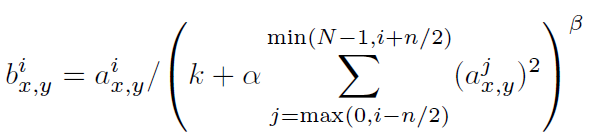
(4) Overlapping Pooling
일반적으로 CNN에서 Pooling은 필터가 겹치지 않고 적용된다. stride = pool size가 되는 것
그러나 AlexNet에서는 이를 겹치도록 사용 stride = 2, pool size = 3으로 설정
이를 Overlapping Pooling => 이렇게 사용하닌 error 가 조금 줄어듦
(5) Overall Architecture
총 8개의 레이어로 구성되어 있음
5개의 Convolutional Layer
3개의 FC Layer - softmax 함수
2,4,5 번째 Convolutional layer들의 커널은 동일한 GPU에 있는 Kernel map에서만 input을 받는다
3번째 Convolutional layer의 경우 모든 Kernel map들로 부터 input을 받는다.
Local Response Normalization의 경우 1-2, 2-3 Convolutional layer 사이에 연결되어 있고
Max Pooling은 1-2 와 2-3, 5-Fc1과 연결되어 있다
Convolutional layer와 Fc layer 모두 ReLU 활성화 함수를 사용 한다
계산과정
1 layer : input (224,224,3) vs kernel (11,11,3) [stride : 4] ➡️ ReLU + LRN + MaxPooling -
2 layer : kernel (5,5,48) ➡️ ReLU + LRN + MaxPooling
3 layer : kernel (3,3,256) ➡️ ReLU
4 layer : kernel (3,3,192) ➡️ ReLU
5 layer : kernel (3,3,192) ➡️ ReLU
1 FC : 4096 ➡️ ReLU
2 FC : 4096 ➡️ ReLU
3 FC : 4096 ➡️ Softmax
Reducing Overfitting
(1) Data Augmentation
과적합을 피하기 위해서 가장 많이 사용되는 방법중 하나로, 기존 데이터를 이동 또는 좌우반전, 회전등을 이용해서 이미지를 랜덤적으로 변화시켜 데이터를 증강시키는 기법이다
Data Augmentation에 대해서는 나중에 따로 살펴 볼것이다
추가적인 이해를 원한다면 아래 블로그 참고 ⬇️
Data augmentation란? 데이터 증강 방법과 예시
Data augmentation는 갖고 있는 데이터셋을 여러 가지 방법으로 augment하여 실질적인 학습 데이터셋의 규모를 키울 수 있는 방법입니다.Andrew Ng의 Data augmentation 소개 영상을 통해 이 개념을 잘 이해해
velog.io
(2) Dropout
기존에는 여러 모델을 학습해서 종합하는 앙상블 기법 (머신러닝에서 많이 사용되고 높은 성능을 낸다)을 사용했다.
그러나 네트워크가 깊어지면 이를 훈련하는데 많은 양의 시간이 소모되기 때문에 앙상블 기법을 사용하기가 어렵다.
(그러나 최근에는 앙상블 기법도 많이 사용한다. 모델의 학습 속도가 많이 상향 되었기 때문이다)
논문이 나올 때는 앙상블 대신에 Dropout을 활용하였는데 이는 모델이 깊어 질 수록 몇몇 뉴력의 결과를 0으로 만드는 것이다. 이렇게 되면 forward나 역전파시 이 뉴런은 전혀 관여를 하지 않는데 이렇게 되면 과적합을 방지할 수 있다
AlexNet의 경우 과적합이 심했는데 Dropout을 사용하고 난 이후 어느 정도 개선되었다고 나온다
Details of learning
Optimizer : SGD (확률적 경사 하강법) + momentum(0.9)
Batch size = 128
learning rate = 0.01 - 처음 -> 학습과정에서 줄어듦
weight decay = 0.0005

learning rate 는 vaildation error가 더 이상 감소하지 않을 경우 1/10만큼 감소 시켰다
Results


'ML 🐼 > 딥러닝 🔫' 카테고리의 다른 글
| [논문 리뷰] CutMix : Regularization Strategy to Train Strong Classifiers with Localizable Features (2) | 2023.03.05 |
|---|---|
| [딥러닝]활성화 함수 (Activation) (0) | 2023.01.11 |
| [딥러닝]규제 Regularization (0) | 2023.01.05 |
| [딥러닝] 옵티마이저 (Optimizer) (0) | 2023.01.04 |
| [논문 구현] 근본을 찾아서... 0. LeNet-5 (GradientBased Learning Applied to DocumentRecognition) (0) | 2022.12.05 |