본 글은 네이버 부스트 캠프 AI Tech 기간동안
개인적으로 배운 내용들을 주단위로 정리한 글입니다
본 글의 내용은 새롭게 알게 된 내용을 중심으로 정리하였고
복습 중요도를 선정해서 정리하였습니다
✅ Week 10
1. 1 Stage Detectors
2. YOLO v1
3. SSD
1. 1 stage Detectors
앞에서 살펴본 2 stage model의 경우 1. Localization을 하고 이를 기반으로 2. Classification을 진행하였다
이러한 방법은 정확성은 꽤 높게 나왔지만 속도가 매우 느리다는 단점이 존재했다
그러면 Real Time에서 Object Detector를 사용할 방법은 없을까?
이러한 의문에서 등장하게된 것이 1 stage Detectors이다
1 Stage model의 대표적인 특징은 RPN 과정이 생략된다는 것이다
그러니까 CNN에서 Feature map을 뽑아서 거기서 객체를 뽑고 여기서 바로 class와 bbox를 뽑는 다는 것이다
즉, Localization과 Classification이 동시에 진행된다
이러한 결과로 Real Time에 사용할 수 있게 되었고
전체 이미지에 대해서 특징 및 객체를 추출하였기 때문에 구조가 매우 간단해졌고
또한 영역을 추출하지 않고 이미지의 전체 맥락을 보기 때문에 Back ground error가 낮아 졌다는 장점이 있다
대표적인 모델로는 YOLO, SSD, RetinaNet이 있다
2. YOLO
YOLO v1 논문(You Only Look Once:Unified, Real-Time Object Detection) 리뷰
이번 포스팅에서는 YOLO v1 논문(You Only Look Once:Unified, Real-Time Object Detection) 논문을 리뷰해보도록 하겠습니다. 2-stage detector는 localization과 classification을 수행하는 network 혹은 컴포넌트가 분리되어
herbwood.tistory.com

You Only Look Onece라는 논문의 제목에서 알 수 있듯이
한번보고 판단하는 모델을 의미한다
YOLO는 1 ~ 7까지의 버전을 갖고 있다
YOLO의 접근 방법은 이미지에서 객체와 객체의 클래스를 동시에 추론하는 방법으로 접근하였다
YOLO의 특징은
Region Proposal 단계가 없고
이미지 전체에서 bbox와 클래스 예측을 동시에 진행한다

Network의 구조는 DarkNet이라는 이름의 넷을 사용했데
이는 GoogleNet을 변형하여서 Featuremap을 추출 하고 이를 2개의 Fc Layer와 연결하여서 box의 좌표와 클래스 확률을 계산한다
Pipline은 다음과 같다
1. 입력 이미지를 S x S 그리드로 나눈다
2. 각 그리드 영역마다 B개의 Bounding Box와 Confidence score를 계산한다
3. 각 그리드 영역 마다 C개의 class에 대한 해당 클래스일 확률을 계산한다

paper 기준으로 계산을 해보면
S = 7, C=20, B=2개 이기 때문에
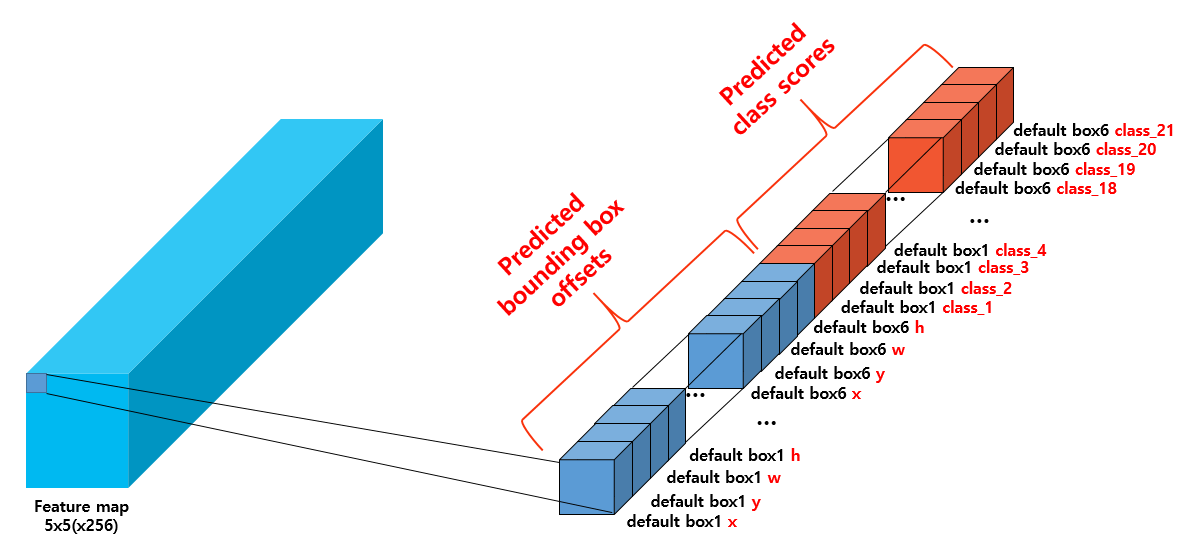
2개의 Bbox - 5개의 값으로 구성 x,y,w,h,confidence +
그리고 20개 Class 확률로 해서 30개의 값으로 하나의 그리드가 구성
그리고 그리드가 7x7이니까
마지막 출력은 7x7x30이 된다
즉, 하나의 Gride에서 2개의 bbox에 대한 클래스확률과 좌표가 나오게 되니까
98개의 bbox 결과가 나오게 될 것이다
그리고 이 결과를 threshold로 거르고 내림차순으로 정렬하여서 NMS 알고리즘을 수행해서
최종 bbox를 결정한다
YOLO의 Loss는 다음과 같다

Localization loss : 각 그리드 셀에 object가 있을때 중심점의 위치를 Regression loss + 각 그리드 셀 object가 있을때 w, h를 Regression
Cofidence loss : 각 그리드 셀에 object가 있을 때 confidence loss 계산 + Object가 없을때 confidence loss 계산
Classification loss : 각 그리드 셀별로 object를 포함하고 있을 때 Class 확률 MSE 계산
YOLO의 장점
1. Faster R-CNN에 비해 6배 빠른 속도
2. 다른 Real-time detector에 비해 2배 높은 정확도
3. 이미지 전체를 보기 때문에 클래스와 사진에 대한 맥락적 정보를 가지고 있음
4. 물체의 일반화된 표현을 학습
3. SSD
SSD 논문(SSD: Single Shot MultiBox Detector) 리뷰
이번 포스팅에서는 SSD 논문(SSD: Single Shot MultiBox Detector)을 읽고 정리해봤습니다. RCNN 계열의 2-stage detector는 region proposals와 같은 다양한 view를 모델에 제공하여 높은 정확도를 보여주고 있습니다.
herbwood.tistory.com
YOLO의 단점은
그리드보다 작은 크기의 물체는 검출하기가 불가능하다는 것과
CNN을 통과한 마지막 feature map만 사용하여 정확도가 낮다는 것이다

따라서 이러한 단점을 해결하기 위해서
SSD가 등장하게 되었다
우선 300 x 300으로이미지의 사이즈를 늘려주고
YOLO의 FC레이어를 제거하고 1 x1 conv를 향상해서 연산량을 줄여주었다
또한 가장큰 특징은
중간중간에 나오는 feature map을 활용해서 Extra convolution layer를 모두 활용해서 detection을 수행하였고
Default box - Anchor box를 사용해서 서로 다른 scale과 비율을 가진 box를 사용하였다
'네이버 부스트캠프 🔗 > ⭐주간 학습 정리' 카테고리의 다른 글
| Unet 계열 - 1편 Unet (0) | 2023.06.14 |
|---|---|
| EfficientDet (0) | 2023.05.10 |
| Neck (0) | 2023.05.08 |
| 2 Stage Detectors (0) | 2023.05.03 |
| mAP - Mean Average Precision (0) | 2023.05.03 |