본 글은 네이버 부스트 캠프 AI Tech 기간동안
개인적으로 배운 내용들을 주단위로 정리한 글입니다
본 글의 내용은 새롭게 알게 된 내용을 중심으로 정리하였고
복습 중요도를 선정해서 정리하였습니다

✅ Week 4
목차
- What is Semantic segmentation?
- FPN
- Unet
- DeepLab
1. What is Semantic segmentation?
우리가 일반적으로 CNN을 활용해서 또는 Attention 기법을 활용해서 CV 문제를 해결한다고 가정을 했을 때
가장 먼저 떠오르는 task는 Image Classifiaction이다
Image Classification의 대표적인 데이터 셋으로는 ImageNet, Cifar 등이 있는데
이런 Image Classification은 한 장의 이미지의 클래스를 분류하는 문제이다
즉, 이미지 안에 위치한 요소들의 공간정보 또는 위치정보는 그닥 중요하지 않다
중요한 것은 이 이미지가 무엇을 나타내고 있는지, 이미지 한장의 전체 맥락이다
이러한 '이미지 분류'문제는 2012년 AlexNet의 등장으로 큰 인기를 얻어왔다
그리고 이미지 분류와 함께 CNN의 방법론을 활용해서 Semantic segmentation이라는 task의 문제도 풀기위하 노력이 나타나기 시작했다
Semantic segmentation과 Image Classification의 큰 차이점은 분류하는 대상의 차이이다

앞에서 살펴 보았듯이 이미지 분류는 사진 전체를 분류하는 문제이다
반면 Semantic segmentation은 이미지 내의 픽셀들의 클래스를 분류하는 문제이다
쉽게 말해서 사진 한장에 사람, 길, 나무가 있다고한다면 이 사람, 나무, 길을 나타내는 클래스를 픽셀연결 짓는 문제이다
추가적으로 Instance Segmentation의 경우에는 Semantic segmentation에서 조금더 복잡해져서
사람들의 사진이 있다면 이 사진의 사람을 사람으로만 구분하는 것이 아니라 서로 다른 사람, 예를 들어 철수 와 영희가 있다면 철수를 나타내는 클래스와 영희를 나타내는 클래스로 -> 물론 사람1 사람2로 나올것이다, 구분하는 것이다
Instance Segmentation은 추후에 다시 다루어 보겠다
다시 Semantic Segmentation으로 돌아가서,
Image Classification와 모델의 구조를 비교해보면
우선 이미지 분류의 경우 Convolution layer를 지나 마지막에 Fully Connected Layer로 연산을 한 이후 Softmax 함수를 통과해서 Class를 나타낸다
하지만 이러한 구조를 통한 과정은 Semantic Segmentation을 할 수 없는 문제점을 만들게 되는데
바로 Fully Connected Layer에서 이미지의 공간 정보를 상실하게 된다는 것이다
즉, 쉽게 말해서 이미지 한장의 정보를 클래스로 맵핑 하기 때문에 중간에 사진 부분 부분의 정보는 필요하지 않다
결국, Semantic Segmentation은 이러한 문제점을 해결하기 위해서 Fully Connected Layer를 Fully Convolution Layer로 대체한다
다음 부분에서 조금더 상세히 살펴보겠지만
1x1 Convolution Layer를 이용해서 이전 Convolution Layer에서 추출된 Feater Map의 모든 픽셀을 연산해서 공간 정보를 유지한채 하나의 출력값을 만들어 내는 것이다
하지만 이러한 Convolution 연산은 이미지의 Size가 줄어드는 DownSampling이 수반될 수 밖에 없다
즉, 이러한 과정에서 이미지의 Size가 줄어드는 것은 필연적이다
이를 해결하기 위해서 Upsampling 과정이 필요한데
단순한 수학적 계산으로 Upsampling을 하는 방법이 있지만 이는 이는 큰 효과를 가져오지 않는다
따라서 Transposed Convolution이나 Deconvolution을 통해서 문제를 해결해 나간다
이 부분을 적용한 FPN을 시작으로 조금더 자세히 살펴보자
2. FPN
FPN은 CNN 모델을 Semantic Segmentation에 적용한 초창기 모델 중 하나이다
Fully Convolutional Networks for Semantic Segmentation
gaussian37's blog
gaussian37.github.io
- 가끔 비전 모델을 공부할 때 참고하는 블로그이다 > 너무 깔끔하게 잘되어 있어서 큰 도움이 된다
앞에서 살펴 보았듯이 1x1 Convolution 연산을 하게 되면 이미지의 사이즈는 줄어드는 결과를 낳을 수 밖에없다
따라서 당연히 Upsampling 과정이 필연적이다
이를 Encoder, Decoder 개념으로 나누어서 설명을 하자면

앞 부분의 CNN Layer는 기존에 pretrained 되어 있는 모델의 CNN layer를 가져와서 이미지의 특징을 추출하여
feature Map을 형성하고 이를 1x1 Convolution한다 -> Decoder 역할
그리고 뒤에 나오는 Upsampling은 이용자의 선택이지만 -> bilinear interpolation과 같은 간단한 계산을 통한 upsampling을 통해서 할 수도 있지만 이는 학습시킬 파라미터가 없기 때문에 정확성이 향상되지 않는다
Transeposed Convolution 연산을 통해서 Upsampling을 시도한다
-> 간혹 이부분을 Deconvolution이라고 하는 사람도 있지만 엄밀한 개념에서는 조금 차이가 있는것 같다 - 어느 시각에서는 Deconvolution 개념안에 Transeposed Convolution이 포함되는 것 같기도 하다
조금더 자세히 살펴보자
2.1 1x1 Convolution
이해를 쉽게하기 위해서 쉽게 설명하자면 마지막 fully connected layer를 convolution layer로 변환시키는 것이다

방법은 아래와 같다

기존 backbone의 FC레이어를 -> (7x7x512) 4096filter conv shape로 변경하게 되면 - 여기서는 VGG모델을 활용
1x1x 4096의 결과를 얻을 수 있다
그리고 앞에 Convolution 연산과정에서 이미지의 사이즈는 줄어들 수 밖에없다
Stride를 2이상으로 하면 반드시 ouptut의 이미지 사이즈는 줄어들기 때문이다
따라서 이를 해결해 주기 위해서 Upsampling이 필요하다
2.2 Upsampling
앞의 convolution 연산과정이 downsmapling이었다면 이제 우리가 할 것은 Upsampling이다
Upsampling 방법에는 여러 방법들이 존재한다
1. Bilinear Interpolation
첫 번째 방법은 Bilinear Interpolation이다
이를 쉽게 설명하자면 - 사실 쉽지 않다

1차원 공간에서 위와 같이 값이 주어지고 오른쪽 조건이 주어졌을 때
우리는 ?까지의 거리를 추론할 수 있다
이러한 방법을 공식화 하면 다음과 같다

Bilinear Interpolation은 이를 2차원 공간으로 확장한 것이다

이제 위의 방법을 활용해서 2x2 -> 4x4로 늘릴때, 그리고 3x3 -> 9x9로 증가시킬때
우리는 추론이 가능해진다
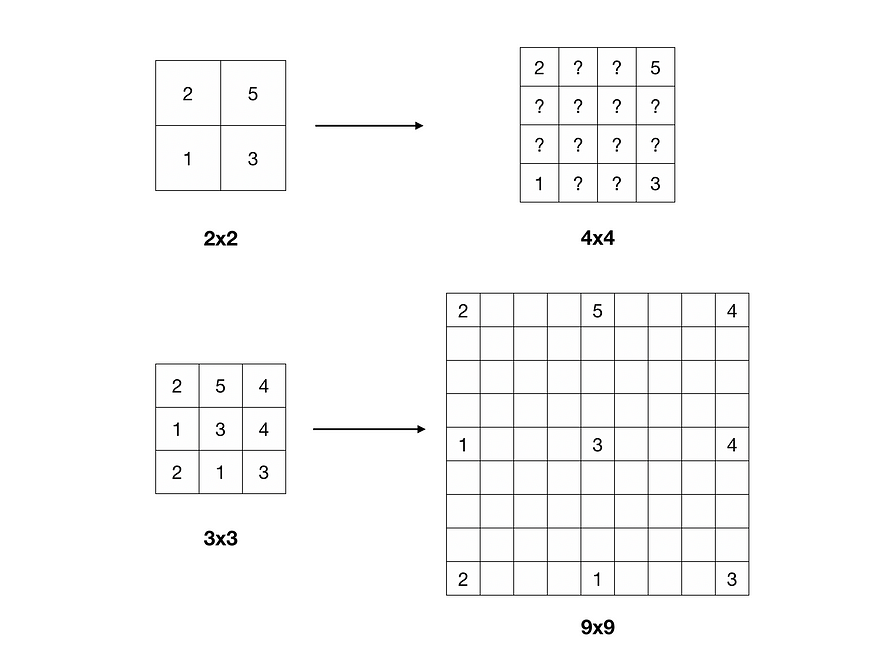
하지만 이러한 방법은 Parameter가 존재하지 않기때문에 학습으로 향상시킬 수가 없다
사실상 수학적 계산만 있기 때문이다
2. strided transpose convolution
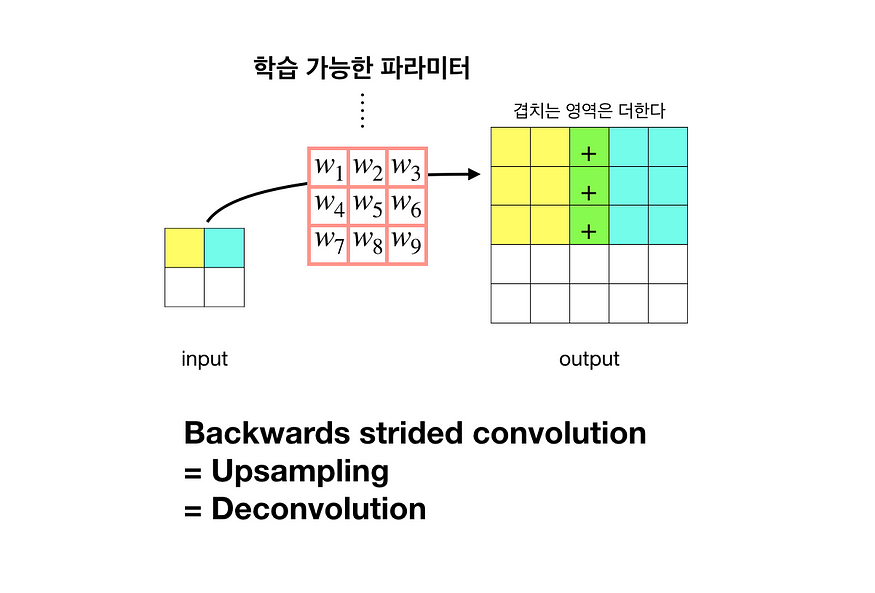
strided transpose convolution은 간단하게 convolution을 반대로 실행하는것이다
따라서 가중치가 생길 것이고 위의 사진처럼
output의 이미지는 더커지게 된다 또한 이 가중치는 학습을 통해서 개선이 되기 때문에 정확성도 증가할 것이다
FCN에서는 두가지 방법을 모두 활용하여 Upsampling을 하였다
이제 input으로 부터 비슷한 크기의 output을 만들어 낼 수 있게 되었다
하지만 여기에 또다른 문제점이 하나가 있다
이는 기존의 input보다 output의 정보가 조금더 축약되어 있기 때문에 결과가 거칠다는 것이다
따라서 이를 개선해주기 위해서 FCN에서는 Skip connection을 활용하였다
2.3 Skip Connection
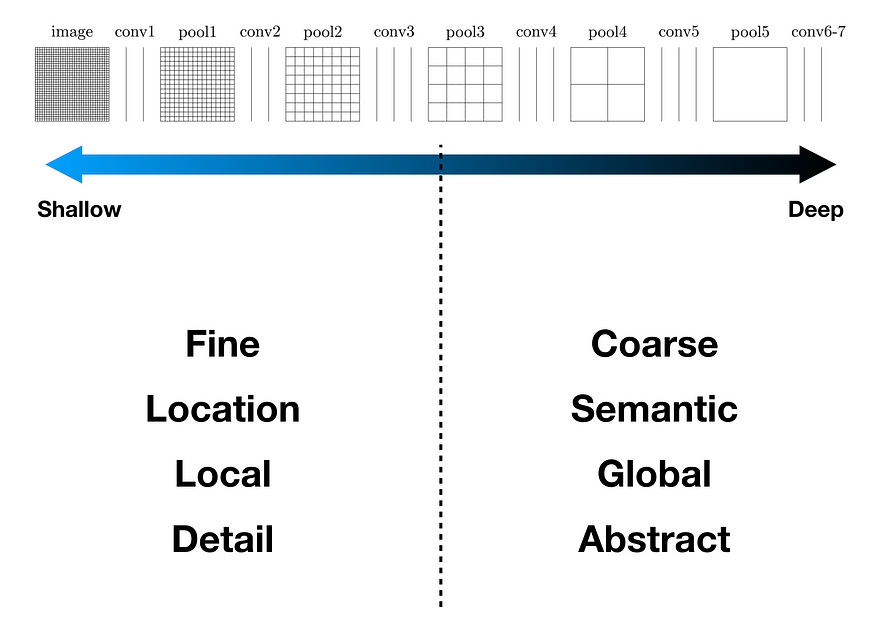
모델이 깊어지면 깊어질 수록 만들어지는 결과는 전체적이고 축약적인 정보이다
따라서 모델이 깊어지기 전의 정보를 가져와서 활용할 수 있다면
추가적인 정보를 얻을 수 있을 것이다 - 먼가 ResNet의 아이디어를 보는 듯 하다
아이디어는 정말간단하다
FPN 논문에서는 이러한 방법을 크게 3가지로 구성해서 모델을 3개로 만들었다


간단하게 skip connection을 사용하지 않은 FCN-32s
그리고 skip connection을 활용한 FCN-16s, FCN -8s- > 이 둘의 차이는 이전 레이어에서 가져오는 정보와 마지막에 Upsampling하는 정도이다
정확도 수는 당연히 앞의 정보를 많이 가져온 FCN-8s가 가장 높다

3. Unet
U-Net, Convolutional Networks for Biom edical Image Segmentation
gaussian37's blog
gaussian37.github.io
U-Net 논문 리뷰 — U-Net: Convolutional Networks for Biomedical Image Segmentation
딥러닝 기반 OCR 스터디 — U-Net 논문 리뷰
medium.com

Unet은 정말 이름부터 직관적인 이름이다
위의사진처럼 U자 모양으로 모델을 구성하기 때문에 Unet이라고 불린다 ㄷㄷ
Unet의 핵심은 크게 3가지 이다
1. Downsampling - 빨간색 부분
2. Upsampling - 파란색 부분
3. Skip-connection - 회색 화살표
사실상 idea는 FCN과 비슷하다고 할 수 있다
하지만 3. Skip Connection의 경우 조금더 앞의 정보를 많이 활용한다는 점에서
더 좋은 결과를 만들고 있는 것 같다
조금더 자세히 살펴보자
3.1 Downsampling - Expanding Path
Downsampling이 방법은 이전의 FCN의 방법과 매우 유사하다
VGG를 백본으로 사용하였고
블록 단위가 변화할 때마다 stride를 늘리면서 사이즈를 줄여나간다
물론 중간에 1번째 블록 단위에서는 padding이 없어서 조금씩 feature map 사이즈를 줄여가고
2번째 블록단위는 그대로 유지했다가 마지막에 2x2 maxpooling에 stride 2를 통해서 줄여나가는 디테일이 있긴하

3.2 Upsampling - Contracting Path
Upsampling은 앞의 Downsampling을 지나온 결과 값들의 사이즈를 늘려나가면서 최종 output을 얻기 위한 과정이다
사실 과정이 FCN과 매우 유사하다

3.3 Skip-connection
물론 FCN의 경우에도 Skip-connection이 존재했다
하지만 Unet의 skip-connection은 조금더 세밀하게 연결을 한다

우선 upsampling과 downsampling의 횟수가 같기 때문에
같은 층에 위치하는 블록들 끼리 skip connection을 한다
여기서 중요한 점은 downsampling 과정에 속했던 블록의 마지막 feature map을 upsampling 첫 번째 input size에 맞춰서 너비와 높이를 자르고 - Cropped 이를 channel 방향으로 concatenation 한다는 것이다
따라서 이렇게 더해진 값을 upsampling의 인풋으로 활용된다
이런 연결은 각 downsampling때 손실되었던? 어느 정도의 정보를 추가해주는 기능을 한다
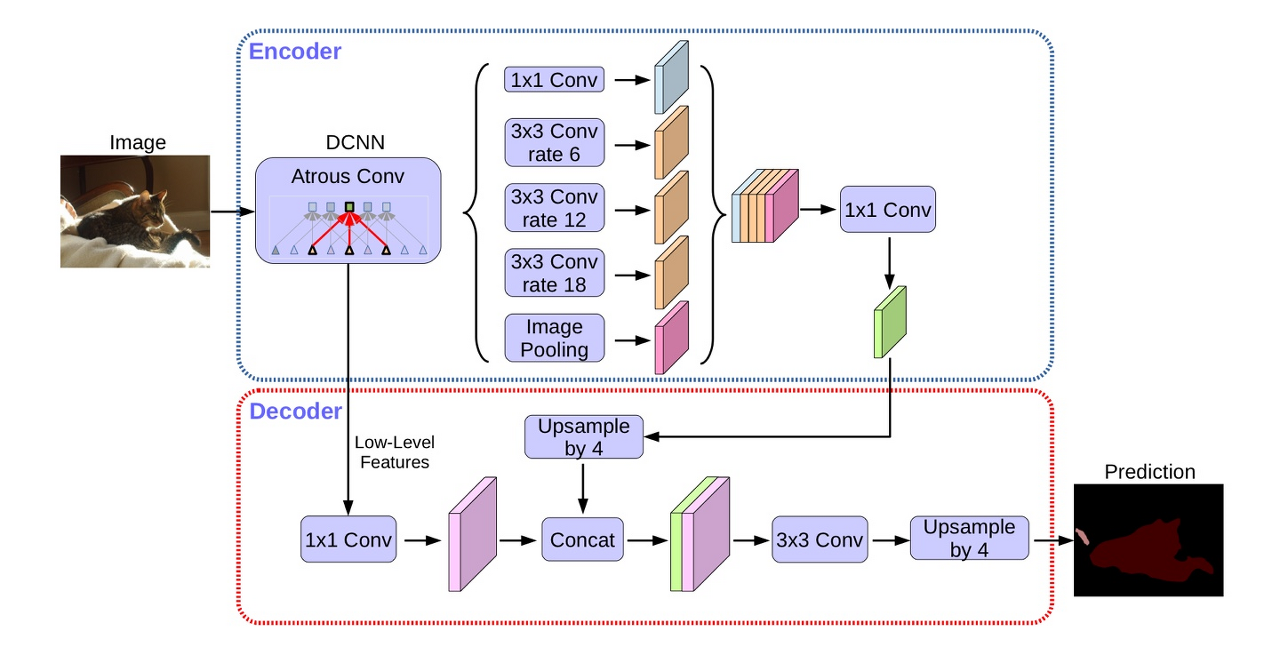
4. DeepLab
DeepLab v3 (Rethinking Atrous Convolution for Semantic Image Segmentation)
gaussian37's blog
gaussian37.github.io

DeepLab은 Downsampling과 Upsampling을 겹치면서 발생하는 정보의 손실을 해결하는 것에 집중을 했다
여기서 중요한 핵심은 위에 사진에도 나타나 있는 Atrous Spatial Pyramid Pooling이다
우선 여기에 활용되는 Atrous Convolution을 알아보자
4.1 Atrous Convolution
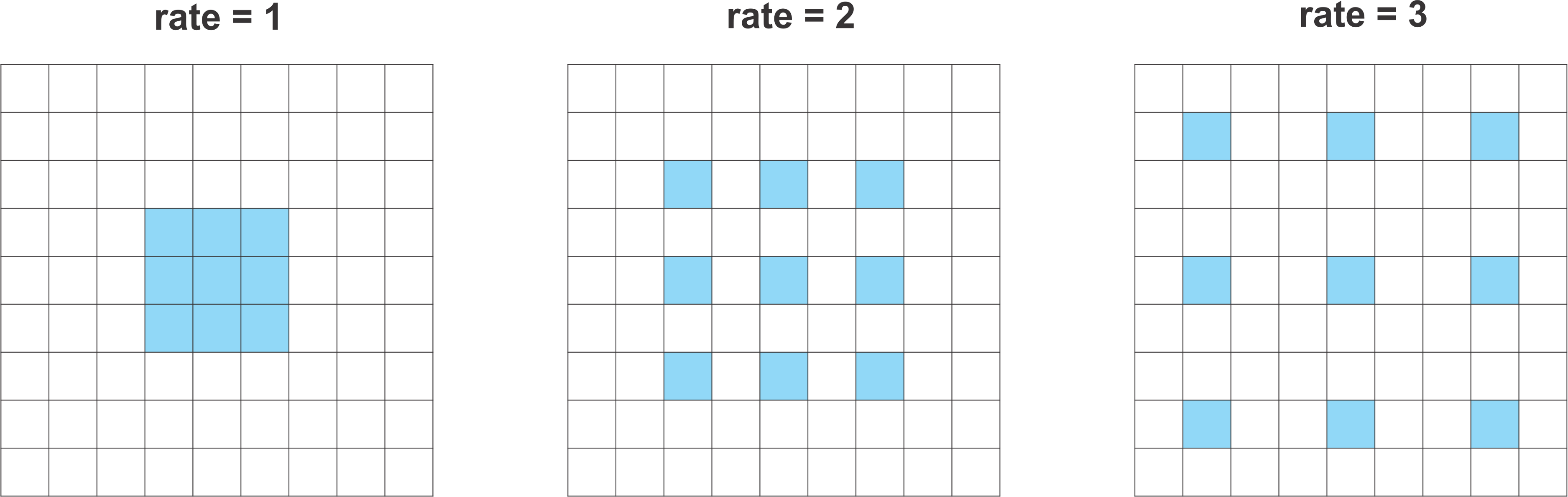
쉽게 말해서 dilation rate 라는 파라미터를 변화시켜서 Dilated convolution을 하는 것인데
비율에 따라서 FOV를 넓게 잡아주거나 좁게 잡아주어서 만들어진 빈공간은 0으로 채운다
이와 같은 방식으로 FOV는 넓히고 파라미터 수와 연산량은 유지하는 방법을 사용하고자 하는 것이 Atrous Convolution이다
여기서 중요한점은 dilation rate를 잘 튜닝해주어야 한다는 것이다

만약 작은 feature map에 큰 dilation rate를 적용하게 되면 3 x 3 convolution이 1 x 1 convolution처럼 적용될 수 있기 때문이다
4.2 Atrous Spatial Pyramid Pooling
이를 쉽게 설명하면 다양한 Atrous Convolution layer를 multi - scale로 적용을 하여서 다양한 multi - FOV를 갖게 만드는 것이다
- ① = 1x1 convolution → BatchNorm → ReLu
- ② = 3x3 convolution w/ rate=6 (or 12) → BatchNorm → ReLu
- ③ = 3x3 convolution w/ rate=12 (or 24) → BatchNorm → ReLu
- ④ = 3x3 convolution w/ rate=18 (or 36) → BatchNorm → ReLu
- ⑤ = AdaptiveAvgPool2d → 1x1 convolution → BatchNorm → ReLu
- ⑥ = concatenate(① + ② + ③ + ④ + ⑤)
- ⑦ = 1x1 convolution → BatchNorm → ReLu
이런과정으로 진행되어서 조금더 다양한 FOV를 확보함으로 조금더 뚜렷한 경계를 만들어 낼 수 있다
그리고 이를 업그레이드 한 Deeplab v3+ 모델도 있다
오늘은 CV task중에서 Semantic segmentation과 다양한 모델들을 알아보았다
이번글에서는 모델의 대략적인 정보만을 포함했기 때문에 디테일한 내용이 빠져있다
따라서 관심이 있다면 각 모델마다 첨부한 블로그 링크에 들어가서 추가적인 설명을 참고하기를 바란다
시간이 된다면 각 모델의 논문을 읽고 논문리뷰로 글을 정리하는 과정을 가져보도록 하겠다
'네이버 부스트캠프 🔗 > ⭐주간 학습 정리' 카테고리의 다른 글
| [부스트 캠프]Week 4 회고 및 Week 5 목표 정리 (0) | 2023.04.02 |
|---|---|
| [네이버 부스트 캠프 AI Tech] Object Detection의 흐름 (0) | 2023.03.31 |
| [네이버 부스트 캠프 AI Tech] Wandb 사용설명서 (0) | 2023.03.29 |
| [네이버 부스트 캠프 AI Tech]Data Augmentation & Efficient Learning (0) | 2023.03.28 |
| [부스트 캠프]Week 3 회고 및 Week 4 목표 정리 (0) | 2023.03.27 |