본 글은 네이버 부스트 캠프 AI Tech 기간동안
개인적으로 배운 내용들을 주단위로 정리한 글입니다
본 글의 내용은 새롭게 알게 된 내용을 중심으로 정리하였고
복습 중요도를 선정해서 정리하였습니다

✅ Week 4
목차
- What is Object Detection?
- Two-stage detector
- Single-stage detector
- Focal loss, RetinaNet
- Transformer in Detection
1. What is Object Detection?
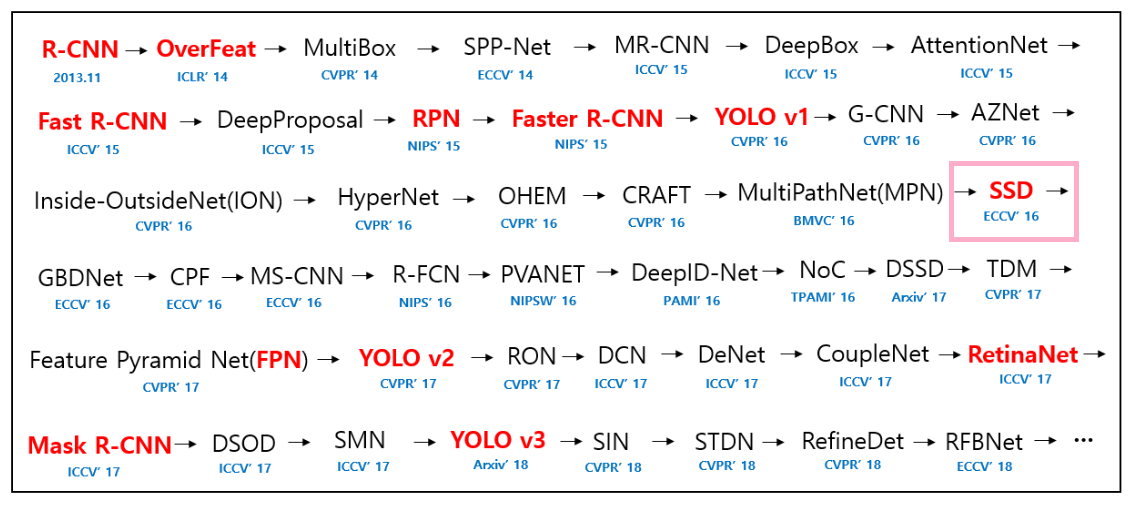
object detection task도 CV 분야에서 오랜시간 발전해온 분야이다
특히, 최근 자율주행과 사람 동작인식 등
산업적인 영역에서 응용될 가능성이 많은 분야이기 때문에 많은 기업들이 기술적으로 보유할려고 하는 분야이기도 하다
object detection은 Bounding Box를 활용한다

쉽게 말해서 이미지 내의 객체가 어디에 위치해 있는지 x1,y1 - x2,y2의 좌표로 표현하여
Box로 표현한 정보이다
object detection은 이러한 bounding box를 활용해서 객체를 Localization하고, 쉽게 말해 어디에 위치해있는지 파악을하고 파악된 객체를 Classification, 클래스를 분류하는 것이다

이러한 과정을 어떠한 방식으로 구성하는지에 따라서 One-Stage와 Two-Stage로 나눠질 수 있다
일반적으로 One-Stage의 경우 Yolo모델 계열이 포함이 되는데 속도는 빠르지만 정확성은 상대적으로 떨어진다
반면 Two-Stage 경우 R-CNN계열이 포함되는데 속도는 느리지만 상대적으로 정확성이 높다
쉽게 두 방법의 차이점을 설명하자면
Two stage model의 경우 위에서 말한 loacalization과 classification을 순차적으로 따로따로 진행을 하고
One stage model의 경우 에는 localization과 classification을 한번에 처리한다는 점이 차이점이다
그럼 지금 부터 각 방법의 모델들을 살펴보면서 자세히 알아보도록 하자
2. Two Stage detector - R-CNN 계열
2.1 R-CNN
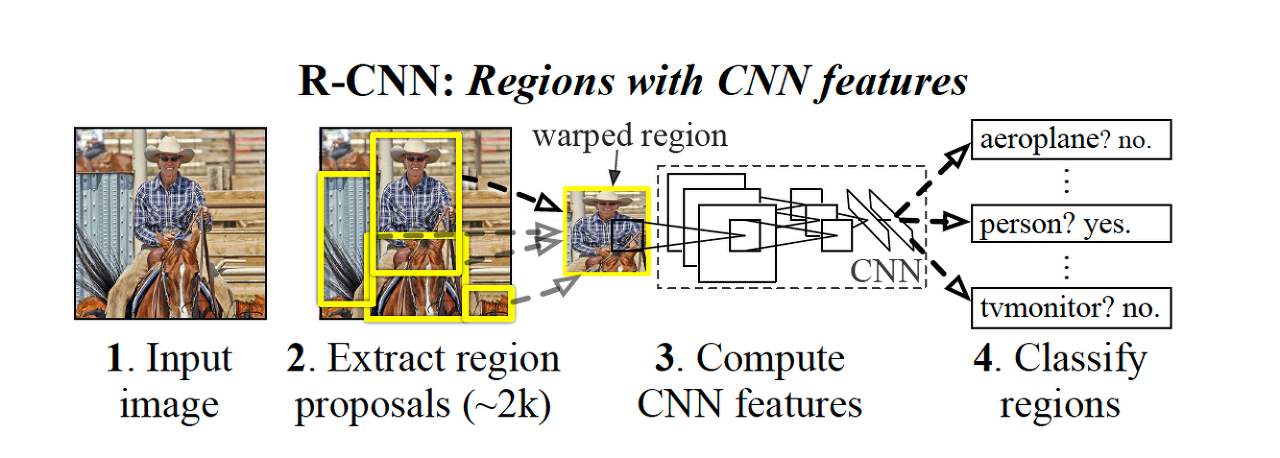
R-CNN은 object detection 분야에 딥러닝 방법론을 최초로 적용시킨 모델이다
Full name은 'Regions with Convolutional Neuron Networks features'로
해석하자면 CNN을 활용해서 지역적인 특징을 추출하는 신경망의 의미를 갖는다
물론 2014년에 나온 모델이기 때문에 현재 Object Detection 분야에서는 잘 사용되지 않는 모델이지만
근본적인 아이디어를 제공했다는 것에서 의미가 있다
언제나 그랬듯 최초로 사용된 모델의 경우 CNN 모델이 분류 문제 뿐만 아니라 다른 task에서도 좋은 성능을 낼 수 있다는 것을 보여주는 것에 집중을 했다 따라서 R-CNN의 최대 단점은 '시간 소요'이다
Two-Stage model의 단점이기도한 이 문제는 근본적으로 Two-Stage model의 공통적인 구조에서 나타난다
우선 R-CNN의 구조를 살펴보자

Two-Stage인 R-CNN은 이름에서 느껴지듯이 2개의 과정으로 나눠진다
하나는 이미지 내에서 객체의 위치를 파악하는 Region Proposal,
다른 하나는 파악된 객체의 클래스를 분류하는 Region Classification이다
R-CNN은 우선 Input이미지에서 bounding box를 만들어내면서 Extract region proposals를 진행한다
쉽게 말해서 객체가 있을듯한 Bounding box를 만들어 내는 것이다
그리고 약 이렇게 2천개의 박스를 만들어 내고 만들어진 박스를 warped 하여- 크기를 고정값으로 변환
CNN - pretrained 에 input으로 넣어서 feature를 추출한다
그리고 이렇게 나온 feature을 SVM을 통해서 classification을 진행하고
다른 단계에서는 bounding box를 regression진행한다
이런식으로 bouding box를 만들고 - > 각 bouding box를 CNN을 통과 시켜 나온 값으로 Classification과 box regression을 하는 것이다
하지만 이러한 방법에는 치명적인 단점이 있다
바로 약 2000개로 만들어진 box를 모두 CNN에 통과하는 시간이 많이 소요된다는 것이다 - 고작 1장 처리하는데
그러면 만약에 10000장의 사진을 처리한다면 2000*10000 -> 2천만번 처리해야한다는 것이다
물론 학습시간때 그런 것이고
추론 시간때는 2000번을 을 진행 -> 그래도 오래걸린다
따라서 real time에 적용하기가 힘들다
2.2 Fast R-CNN
위의 문제를 어느 정도 개선한 방법이 바로 Fast R-CNN이다
이름에서도 느껴지듯이 빨라졌다
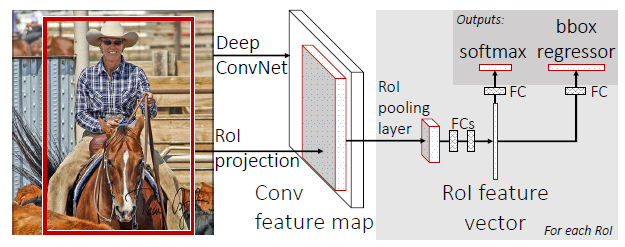
Fast R-CNN은 각 bounding box를 CNN을 통과시키는 방법을 개선해서
먼저 input image를 CNN에 넣어서 통과시키고 이를 Rol pooling으로 고정된 벡터로 만들어 준다음
이렇게 만들어진 feature map에 Selective Search로 영역을 만들어내어
selective search? :
Selective Search 간단히 정리..
Selective Search - 기존의 exhaustive search의 방식의 비효율성으로 "object가 있을 법한 영역만 찾는 방법"이 제안됨 - 이를 region proposal - 이 후 detector는 1) generic detector로 candidate objects 영역을 찾기 위해 ex
better-tomorrow.tistory.com
classification과 box regressor를 진행하는 방법이다
즉, 기존에 엄청많이 CNN을 통과 해야했던 것과 다르게 한번만 통과하는 방법으로 변화시켜서
어느정도 속도를 줄인 것이다
하지만 selective search로 영역을 만들었기 때문에 실시간 적용에는 아직도 어려움이 있었고
end - to - end 학습이 불가능했다
2.3 Faster R-CNN
앞에 모델과 이름이 비슷하지만 조금더 성능을 개선한 모델이 Faster R-CNN이다 - 무려 er을 붙였다
Faster R-CNN은 기존의 Fast R-CNN의 selective search를 개선하여 Region Proposal Netwokr를 만들어 anchor boxes를 생성하는 것으로 변환하여 속도를 조금더 개선하였다
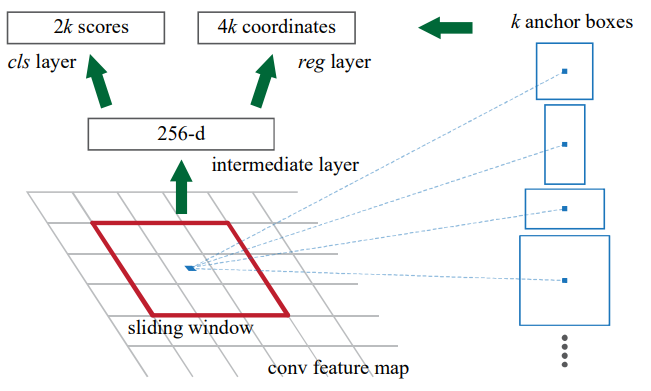
RPN을 간단하게 설명하자면
우선 CNN을 통과한 Feature Map- 예를 들어 7x7 feature map이라고 한다면 에 kernel을 Sliding window 방식으로
각 격자에 k개의 Anchor box를 정의한다 -> Anchor 박스는 9개의 크기로 논문에서 제안한다
즉 49*k*channel개의 박스가 하나의 feature map에 만들어 지는 것이다
그리고 이렇게 만들어진 feature map에 Bouding Box Regression과 Classification을 따로 진행하여서
최종 output을 만들어낸다
[논문정리] RCNN, Fast RCNN, Faster RCNN 핵심!
이번 포스팅은 Object Detection 중 2-Stage Detector의 큰 흐름이라고 할 수 있는 R-CNN 계열에 대해 정리해보겠습니다. 이미 블로그, 유튜브를 포함한 많은 곳에서 R-CNN 계열을 설명하고 있으므로, 이번 포
wsshin.tistory.com
하지만 이러한 Two stage의 치명적인 단점은 시간이다
어쩔 수 없이 Box regressor와 Classification을 따로 진행하기 때문에
시간이 많이 소요될 수밖에 없다
이러한 과정을 한번에 처리하는 방법을 제안한 것이 One Stage model이다
이제 one stage model, 또는 Single stage modeldel에 대해서 알아보도록 하자
3. Single-stage detector
3.1 Yolo

Yolo는 최근까지 계속해서 버젼을 업데이트하고 성능을 개선하면서
object detection에서 많은 사랑을 받고 있는 모델이다
Yolo의 큰 장점은 처리시간이 빠르다는 것에 있다
그리고 모델도 가볍다
따라서 실질적으로 real time에 적용하고 싶을 때는 Yolo를 많이 사용한다
물론 yolo가 처음 제안될 때 State of art model들 보다 조금 성능이 떨어졌지만
처리 시간이 엄청 빠르다는 장점때문에 큰 관심을 받았다
Yolo 속도의 비결은 Classification과 Box regressor를 한번에 진행한다는 것이다
방법에 대해서 자세히 살펴보면
우선 input image를 S x S의 격자로 나누고 만약 객체의 중심이 격자에 포함된다면
그 격자에 detection 의무를 부여한다
그리고 각 격자마다 bounding box를 B개를 만들어 내고
confidence score을 만들어낸다
여기서 confidence score는 박스가 물체를 포함하는지와 얼마나 정확히 포함하는지를 반영하고 있다
따라서 이렇게 구성된 격자를 통해서 Classification과 box regressor를 동시에 진행하는 것이다
자세한 내용은 논문리뷰로 다시 정리해보겠다
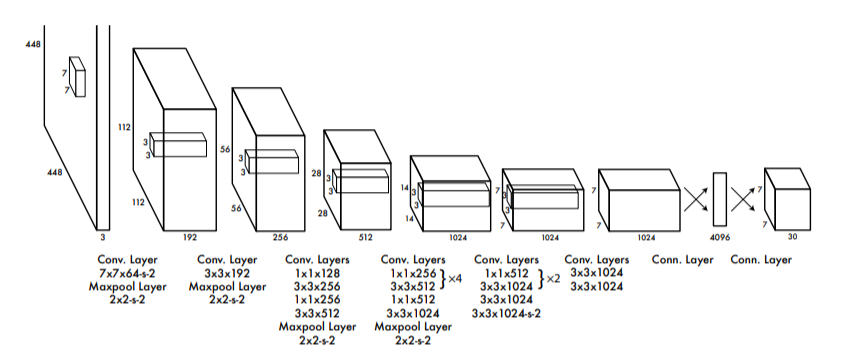
Yolo의 구조는 간단하게 앞에서 Pre trained 된 CNN 모델을 활용해서 feature를 추출하고
이를 통해서 마지막에 fully connected layer를 추가해서 box regressor와 classiciation을 동시에 진행한다
Yolo는 마지막에 예측을 한번만 하기 때문에 localization이 떨어진다는 단점이 있다
3.2 SSD

SSD는 우선 격자의 크기마다 bounding box 크기에 제한을 두어서 조금더 잘맞는 제한을 두었고
각 레이어를 통과하면서 만들어진 각각의 feature map에서 classifier를 통과하기 때문에
조금더 다양한 scale에서 정보를 추출하여서 정확성을 증가시켰다
성능면에서 Yolo보다 좋고 심지어 Faster-R-CNN 보다 좋은 성능을 보여주었다
4. Focal loss , RetinaNet
Single Stage model의 경우 ROI pooling이 없기 때문에
이미지 내의 모든 영역에서 loss가 계산된다

이러한 결과는 문제를 만들어내는데
일반적인 이미지 데이터에서는 배경의 영역이 더 크고 객체의 영역은 상대적으로 작은데
이러한 문제는 전체 영역의 loss를 계산하게되면 Class imbalance 문제가 발생하게 된다
이러한 문제를 해결하기 위해서
Focal lossr가 제안되었는데 이부분은 밑에 블로그님이 잘 정리를 해주셔서 참고하기를 바란다
Focal Loss (Focal Loss for Dense Object Detection) 알아보기
gaussian37's blog
gaussian37.github.io
그리고 focal loss를 제안하는 논문에서 RetinaNet이라는 모델 또한 제한되었다

RetinaNet 논문(Focal Loss for Dense Object Detection) 리뷰
이번 포스팅에서는 RetinaNet 논문(Focal Loss for Dense Object Detection)을 리뷰해도록 하겠습니다. Object detection 모델은 이미지 내의 객체의 영역을 추정하고 IoU threshold에 따라 positive/negative sample로 구분한
herbwood.tistory.com
5. Transformer in Detection
또한 최근에는 자연어 분야에서 인기를 얻은 Attention 모델을 가져와서
object detection에 적용한 DETR등 다양한 Transformer 모델들도 등장하고 있다

(DETR) End-to-End Object Detection with Transformers 리뷰
원문 : Carion, Nicolas, et al. “End-to-End Object Detection with Transformers.” arXiv preprint arXiv:2005.12872 (2020). 본 글은 Facebook AI에서 2020년 arxiv에 발표한 End-to-End Object Detection with Transformers (DETR) 논문에 대한 리
rauleun.github.io
3) DETR (Detection with Transformer)
지금까지 object detection 모델을 설명하기 위해서 Region proposal, Anchor box, NMS 등등 새로운 개념들이 많이 등장했습니다. 이런 개념들은 …
wikidocs.net
'네이버 부스트캠프 🔗 > ⭐주간 학습 정리' 카테고리의 다른 글
| [네이버 부스트 캠프 AI Tech] Instance & Panoptic Segmentation (0) | 2023.04.03 |
|---|---|
| [부스트 캠프]Week 4 회고 및 Week 5 목표 정리 (0) | 2023.04.02 |
| [네이버 부스트 캠프 AI Tech] Semantic segmentation의 흐름 (0) | 2023.03.30 |
| [네이버 부스트 캠프 AI Tech] Wandb 사용설명서 (0) | 2023.03.29 |
| [네이버 부스트 캠프 AI Tech]Data Augmentation & Efficient Learning (0) | 2023.03.28 |