본 글은 네이버 부스트 캠프 AI Tech 기간동안
개인적으로 배운 내용들을 주단위로 정리한 글입니다
본 글의 내용은 새롭게 알게 된 내용을 중심으로 정리하였고
복습 중요도를 선정해서 정리하였습니다

✅ Week 2
목차
- torch.nn.Module
- torch.nn.Module?
- nn.Parameter
- forward & backward
- PyTorch Dataset
- Dataset
- Dataloader
1. torch.nn.Module
우리가 딥러닝 논문을 구현한다고 가정해보자

벌써부터 어지럽다고 생각할 수 있다
걱정하지마라 우리는 지난 시간에 배운 'Pytorch'가 있다
우리가 딥러닝 모델 건축한다고 했을 때 'Pytorch'는 강력한 건설장비가 된다
자 그럼 이제 전문가가 되어 건축을 시작해보자

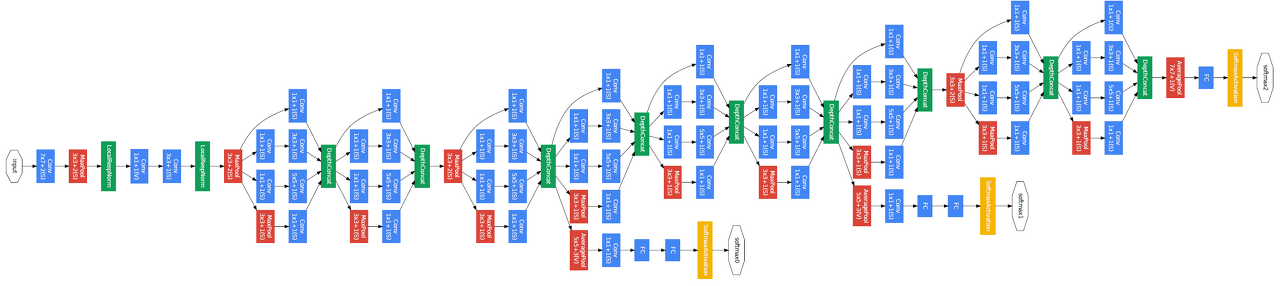
" 시작부터 난제를 만났다 "
엄청나게 복잡해보이는 구조가 눈앞에 나타난 것이다
- 사실 내용을 뜯어보면 할만하다
자세히 살펴보면 뭔가 비슷한 블록들이 반복해서 연결되어 있는 것을 확인할 수 있다.
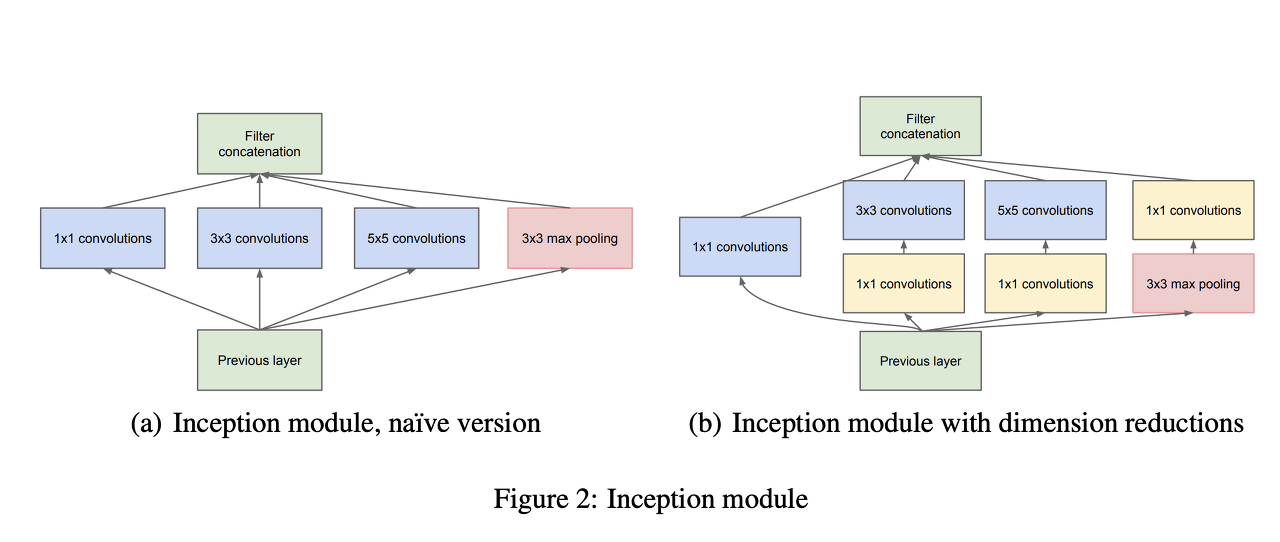
사실 Inception V1의 경우 Inception module이라는 블록의 연속이다
이번에는 Inception module을 자세히 살펴보자
convolution 연산 블록의 연속인게 눈에 들어온다...
마침내, 우리는 딥러닝의 모델이 여러 블록의 연속이라는 사실에 도달했다
그렇다면 우리는 이러한 블록을 모델 구현과정에서 일일이 다 구현해야할까?
" 정답은 No "
앞에서 말했듯이 우리에게는 Pytorch가 있다
이제 우리는 신이고 무적이다
사실 Pytorch가 신이고 무적이다
torch.nn.Module
이 Class에 우리가 필요한 모든게 구현되어 있다 - 사실 조금은 없을지도..
마치 원피스 같은 공간이다
이 파트에서는 이러한 torch.nn.Module에 대해서 자세히 살펴보려고 한다
torch.nn.Module (이하 nn.Module로 부르겠다)은 딥러닝을 구성하는 가장 기본적인 Class 역활을 한다.
이게 무슨말인가 하면
딥러닝에서는 Input, output, forward-순전파, backward-역전파의 과정이 필요하다
즉, 위의 과정을 nn.Module에 구현하면 자연스러운 Flow로 흘러가게 해준다.
한번 코드로 작성해서 직접살펴보자
import torch
import torch.nn as nn
class SimpleLinear(nn.Module):
def __init__(self, in_features, out_features, bias = True):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.w = nn.Parameter(
torch.randn(in_features, out_features))
self.b = nn.Parameter(torch.randn(out_features))
def forward(self, x):
return x @ self.w + self.b위 클래스는 nn.Module을 활용해서 만들어준 간단한 선형회귀 모델이다
__init__에서 입력과 출력의 크기를 받아서 랜덤한 가중치와 bias를 생성해주었다
그리고 foward 부분은 이러한 가중치와 bias가 input값을 받았을 때 흘러가는 순전파 계산이 실행되는 곳이다
여기서 눈에 띄는게 있다 바로 nn.Parameter이다
이것은 무엇일까?
nn.Parameter
쉽게 말해서 미분가능한 Tensor이다
즉, 기존에 있는 Tensor 클래스를 받아와 required_grad = True인 상태로 하여서
미분을 가능하게 해주는 것이다
물론 위 코드에서 nn.Parameter를 사용하지않 torch.Tensor를 활용해서 사용할 수 있고
output이 나오는 과정에는 영향이 없다
그럼 무슨 차이점이 있을까?
class TensorLinear(nn.Module):
def __init__(self, in_features, out_features, bias = True):
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.w = torch.Tensor(
torch.randn(in_features, out_features))
self.b = torch.Tensor(torch.randn(out_features))
def forward(self, x):
return x @ self.w + self.bTensor를 활용해서 위와 똑같은 모델을 만들었다
이제 이 두 모델의 차이점을 비교해보자
layer1 = SimpleLiner(7, 12)
for value in layer2.parameters():
print(value)
>>> Parameter containing:
tensor([[-2.4298, -1.3621, -0.0608, -0.0993, 0.5903, -0.1235, -1.3430, 0.3945,
0.9228, 0.0514, 1.0512, 0.3789],
[ 1.6015, -0.8470, -1.4088, 2.9261, 2.0493, 0.4330, 2.3871, -0.6038,
-1.1008, -1.5703, -2.4947, 0.1285],
[ 0.9175, -0.4259, -1.2068, -0.7784, -0.6996, -1.5650, 1.7471, 0.1587,
-0.0890, 1.1944, 1.0161, 0.8549],
[-0.7396, 0.0796, 0.4474, -0.8191, 0.6164, -0.0566, 0.3292, -1.5526,
0.1288, 0.4044, 1.1065, 0.5567],
[ 0.4181, -0.5928, 0.1495, 0.3841, -1.3590, 0.1286, -0.6780, 1.0562,
1.2685, -0.0684, -0.0061, -0.0337],
[ 1.6698, -0.1637, 1.1237, 1.7584, 0.3426, 0.3749, 0.9552, -0.4359,
0.4972, 0.6720, -0.2464, 0.1360],
[-1.3653, 0.1722, -1.3602, -0.7758, -1.1258, 1.1127, 1.7281, 1.0423,
1.1524, 0.3689, 0.6811, -0.0606]], requires_grad=True)
Parameter containing:
tensor([-0.4975, 0.7173, 0.5902, 1.3909, -0.3948, 0.4428, -0.5536, 1.2566,
0.5645, -0.5961, -1.2501, -0.9032], requires_grad=True)
layer2 = TensorLinear(7, 12)
for value in layer2.parameters():
print(value)
>>> ???차이점이 보이는가?
nn.Parameter를 활용해주면 model.parameters()해주었을 때 가중치와 bias가 표시되었지만
Tensor를 활용한 model은 표시되지않는다
이는, .parameters()는 미분가능한 대상만 표현하기 때문이다
그리고 여기서 가장 중요한것
사실 nn.Parameter를 사용할 일은 거의 없다
왜냐하면 이미 nn.Conv2D와 같이 특정 Layer의 경우 Pytorch에 이미 구현되어 있고
특수한 상황이 아닌이상 우리가 직접 가중치를 생성할 일은 잘 없다
forward & backward

여기까지 왔으면 어느 정도 nn.Module에 대한 이해가 거의 다 되었을 것이다
이제 살펴볼것은 forward와 backward이다
사실 forward의 경우 이미 살펴보았다
앞의 모델에서 def forward부분이다
즉, 모델의 순전파 부분인 것이다
이러한 forward는 input 값을 주었을 때 output이 나오게 하는 흐름으로
input만 넣어주면된다
즉, forward 부분으로 구현해놓으면 끝인 부분이다
사실 우리는 Linear, Conv2D와 같은 이미 구현된 layer를 사용하기 때문에 전체 모델의 forward를 만드는 경우가 아니면 직접 forward를 구현하지 않아도 된다
그렇다면 앞에서 구현한 모델의 역전파 backward는 어떻게 진행될까?
미분은 사실 nn.Module에 구현되어있다
간단하게 말해서 AutoGrad 자동 미분이 만들어져 있는것이다
어떻게 사용할 수 있을까?
import torch
class Simple(torch.nn.Module):
def __init__(self, input, output):
super(Simple, self).__init__()
self.linear = torch.nn.Linear(input, output)
def forward(self, x):
out = self.linear(x)
return outtorch.nn.Linear를 활용해서 아주 간단한 모델을 만들었다
사실 맨 처음 모델과 같은 기능이다
여기서 이제 backward를 진행하는 과정을 살펴보자
import numpy as np
#데이터생성
x_values = [i for i in range(11)]
x_train = np.array(x_values, dtype=np.float32)
x_train = x_train.reshape(-1, 1)
y_values = [2*i + 1 for i in x_values]
y_train = np.array(y_values, dtype=np.float32)
y_train = y_train.reshape(-1, 1)
lr = 0.01 #학습률
epoch = 100 #에폭
model = Simpler(1,1) #인풋, 아웃풋 차원들 설정
#GPU를 쓴다면
if torch.cuda.is_available():
model.cuda()
criterion = torch.nn.MSELoss() #loss값
optimizer = torch.optim.SGD(model.parameters(), lr=learningRate) #최적화방법
for epoch in range(epochs):
# Converting inputs and labels to Variable
if torch.cuda.is_available():
inputs = Variable(torch.from_numpy(x_train).cuda())
labels = Variable(torch.from_numpy(y_train).cuda())
else:
inputs = Variable(torch.from_numpy(x_train))
labels = Variable(torch.from_numpy(y_train))
# Clear gradient buffers because we don't want any gradient from previous epoch to carry forward, dont want to cummulate gradients
optimizer.zero_grad()
# get output from the model, given the inputs
outputs = model(inputs)
# get loss for the predicted output
loss = criterion(outputs, labels)
print(loss)
# get gradients w.r.t to parameters
loss.backward()
# update parameters
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))코드가 길다
쫄지마라 우리가 확인할 부분은 for문이니까
for epoch in range(epochs):
if torch.cuda.is_available():
inputs = Variable(torch.from_numpy(x_train).cuda())
labels = Variable(torch.from_numpy(y_train).cuda())
else:
inputs = Variable(torch.from_numpy(x_train))
labels = Variable(torch.from_numpy(y_train))
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
print(loss)
loss.backward()
# update parameters
optimizer.step()
print('epoch {}, loss {}'.format(epoch, loss.item()))간단히 설명하면 for문 동안 즉, 우리가 설정한 epoch동안 학습이 진행된다
optimizer.zero_grad()는 이전 optimizer에 활용된 미분을 초기화 시켜주는 것이고 - 이전 현재 에폭에 영향을 x
outputs는 모델이 예측한 y'을 만들어낸다
그리고 이를 criterion에 labels - 실제 y값과 함께 넣어서 loss를 계산하고
이렇게 만들어진 loss를 통해서
loss.backward()를 진행하여서 역전파를 실행하여 미분을 구해준다
그리고 optimizer.step()를 사용해서 구해진 미분으로 최적화를 실행한다
이런식으로 모델의 가중치와 bias를 조정해주는 것이다
이것이 backward의 과정이다
위 과정이 model train에서 대부분 사용되는 방법이다
복잡했던 미분이 loss.backward() 하나로 완료되는 것이다
간단하죠?
그럼 이렇게 학습된 모델이 test data를 활용해 예측치를 어떻게 만들어 낼까?
from torch.autograd import Variable
with torch.no_grad():
if torch.cuda.is_available():
predicted = model(Variable(torch.from_numpy(x_train).cuda())).cpu().data.numpy()
else:
predicted = model(Variable(torch.from_numpy(x_train))).data.numpy()
print(predicted)매우 간단하다 우선 with구문으로 torch.no_grad()를 실행한다
이말은 추론과정에서 gradient를 실행하지 않겠다는 것으로 test data가 모델 가중치에 영향을 주지 않게 만드는 것이다
그리고 간단하게 model에 데이터를 넣으면
예측값이 나온다
쉽죠?

2. Pytorch Dataset
지금까지 살펴본 것은 Model을 어떻게 만들 수 있는지이다
그럼, 지금 부터 살펴볼 것은 Model에 들어가는 Data를 어떻게 요리할 수 있는지 살펴보겠다
비유적으로 표현하자면
앞에서 살펴본 것은 집을 만드는 건축이었다면
지금 부터 살펴볼 것은 그 집에 들어가는 가구의 배치를 하는 아기자기한 인테리어다
우리에게 Data가 있다

벌써부터 심장이 두근된다
우리가 만든 데이터를 앞에서 만든 모델 같은 형태에 넣기만 하면
딥러닝이 완료된다니....
하지만 현실은 그렇게 쉽지않다
pandas의 데이터 프레임을 그냥 모델에 집어 넣는다고
딥러닝 모델이 무엇이 데이터이고 무엇이 y값인지 구별할 수 있을까?
정답은 No이다
그렇다면 우리는 알맞은 형태로 Data를 넣어주어야한다
그럴 때 사용되는 것이 Dataset이다
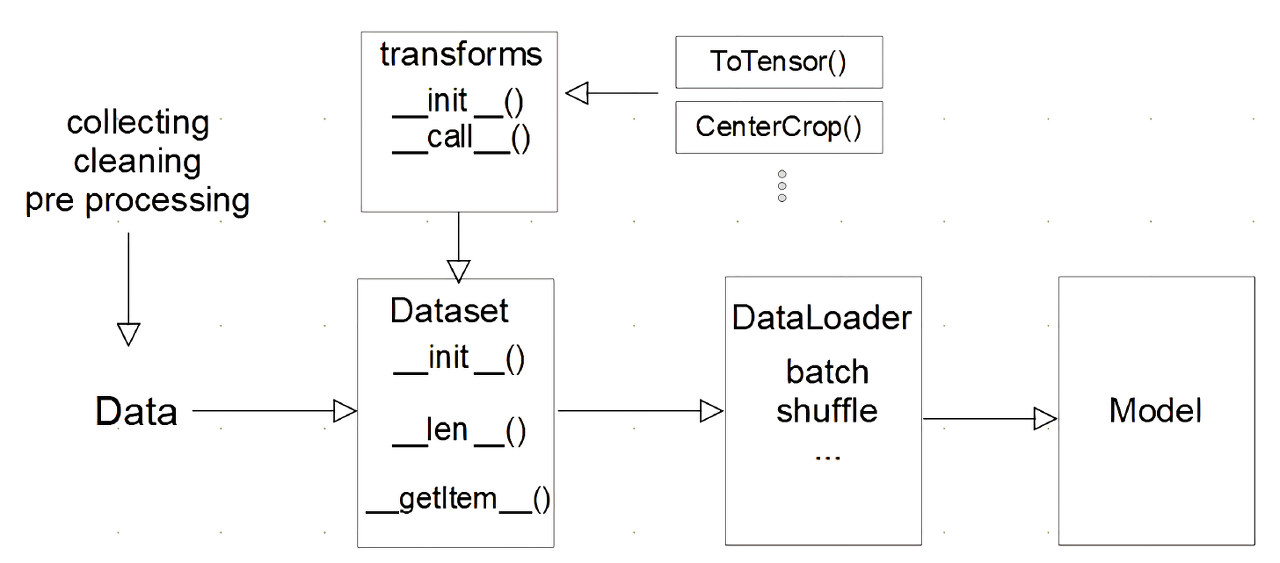
DataSet class
쉽게 말하자면 데이터 입력 형태를 정의하는 클래스이다
데이터에 맞게 규칙을 정하고 정형화 해서 모델에 입력할 수 있게 만들어 주는 클래스이다
코드로 구현 하면 간단하다
import torch
form torch.utils.data import Dataset ## torch.utils.data에 위치
class MyDataset(Dataset)):
def__init__(self, text, labels):
self.data = text
self.y = labels
def__len__(self):
return len(self.y)
def__getitem__(self, idx):
y = self.y[idx]
x = self.data[idx]
return x, y
정말간단하다
사실 nn.Module과 비슷해 보인다
기능은 간단하다 데이터를 input으로 받아서
return 값을 지정해주는 이는 우리가 지정해줄 모양으로 정해줄 수 있다
또한 len()을 사용하면 데이터의 전체 크기도 반환해 준다
이렇게 데이터 셋을 구성하면 장점이 무엇일까?
일단 다른 사람과 코드를 공유할 때 매우 편하다 - 표준화, 정형화
누가봐도 무엇이 데이터의 x이고 y인지 한눈에 보인다
또한 다양한 시점에서 변화를 줄 수있다
이는 자연어처리에서 조금 많이 사용되는 것같은데
데이터를 input으로 주기 전에 토큰화라든지 전처리를 실행하여서 dataset에 넣어 줄 수있다
하지만 이는 추후에 새로운 데이터가 추가되었을 때 다시해야한다는 귀찮음을 만들어낸다
결국 Dataset에 이를 구현해 놓으면
input으로 데이터를 넣기만 해도
추가된 데이터의 전처리를 실행할 수 있다 - 매우 효율적이다
그러면 이렇게 만들어진 Dataset을 모델에 때려 박으면 될까?
가능하다
하지만 데이터의 양이 많아지면 많아 질 수록 효율성이 쓰레기일 것이다
또한 Tensor로 변환하는 과정에서 갑자기 GPU로 대용량의 데이터가 갑자기 들어오면
병목현상이 벌어지게 될것이도
당신의 GPU는 사망할 수도 있습니다...
이를 위해서 제공되는 Pytorch의 또다른 Class - DataLoader가 있다

DataLoader
DataLoader의 경우 우리가 만든 Dataset을 input을 넣어주고 batch_size를 입력해주면
Dataset을 batch 사이즈로 잘라준다
쉽게 코드로 보자
frofrom torch.utils.data import DataLoader
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
next(iter(MyDataLoader))
>> X, y가 출력됨 (배치사이즈 만큼)너무 간단한다 그리고 shuffle이라는 파라미터은 batch로 구성되는 데이터를 섞어서 구성한다
즉, 1,2,3,4,5,6 데이터가 들어가고 batch_size가 2일 때
shuffle =Fasle이면
[1,2], [3,4], [5,6]이라면
shuffle = True인 경우
[1,4], [2,5], [6,3] 같이 랜덤적으로 구성된
참고로 DataLoader는 Generator이다
Python Generator에 대해서 :
[Python] Iterator vs. Generator
파이토치를 하다보면 특히, DataLoader 다루다보면 Generator 라는 것을 만나게 된다 처음 마주치면 어떠한 개념인지 살짝 애매할 수 있기 때문에 이번에 개념을 한번 글로 정리해보려고 한다 Iterator v
eumgill98.tistory.com
DataLoader에는 다양한 하이퍼파라미터가있다
이를 정리한 글 :
[Pytorch] DataLoader parameter별 용도
pytorch reference 문서를 다 외우면 얼마나 편할까!!
subinium.github.io
'네이버 부스트캠프 🔗 > ⭐주간 학습 정리' 카테고리의 다른 글
| [네이버 부스트 캠프 AI Tech] OOM & Multi GPU & Hyper parameter tune (0) | 2023.03.16 |
|---|---|
| [네이버 부스트 캠프 AI Tech] Pretrained Model & Training Monitoring (2) | 2023.03.15 |
| [네이버 부스트 캠프 AI Tech] Pytorch 기본 (0) | 2023.03.13 |
| [부스트 캠프]Week 1 회고 및 Week 2 목표 정리 (0) | 2023.03.13 |
| [네이버 부스트 캠프 AI Tech] CNN & RNN (0) | 2023.03.10 |