본 글은 네이버 부스트 캠프 AI Tech 기간동안
개인적으로 배운 내용들을 주단위로 정리한 글입니다
본 글의 내용은 새롭게 알게 된 내용을 중심으로 정리하였고
복습 중요도를 선정해서 정리하였습니다

✅ Week 2
목차
- Manage OOM
- Mult-GPU
- Hyper parameter tune
*주의 : 이번 내용은 실습적인 코드보다는 이론적인 설명을 중심으로 전개하였습니다.
실습코드와 상세한 기술까지 작성하면 글의 분량이 길어질 것 같아서
해당 부분에 포함되는 실습 내용은 각각 추가 내용정리에 추후에 *강조* 정리하겠습니다
✅ Intro 다시 돌아온 도비

다시 도비가 돌아왔습니다
그동안 도비는 다양한 모델을 돌려보고 pytorch에 대한 이해도를 얻었습니다
그러던 중 도비는 다양한 에러들을 맞이 했습니다
특히, OOM - out of memory는 도비를 화나게했습니다 🔥🔥🔥🔥

어떻게 해서든 문제를 해결하기 위해서 방법들을 알아보았습니다
우리도 함께
✅ 1. Manage OOM

도비가 딥러닝을 학습할 때 나타나는 위의 코드는
사실상 볼트모트와 같습니다...
마치 죽음의 저주를 내린 것과 같습니다

다행스럽게도 이런 저주를 푸는 방법이 존재합니다
고대 마법같은 방법이죠
이번 파트에서는 도비와 함께 이런 방법들에 대해서 알아보도록 하겠습니다
그전에 우선 이 악마같은 OOM에 대해서 알아보도록 하겠습니다
⭐What is OOM
OOM - out of memory입니다
이러한 상황의 단점은 무엇일까요??
당연히 가장큰 문제는 오류가 발생해서 학습을 돌릴 수가 없다는 것이죠...
그럼 또다른 문제는 무엇일까요?
- 왜 발생했는지 원인을 알 수가 없습니다
- 그리고 메모리 이전 상황을 파악하기가 힘들어 어디서 부터 문제인지 알 수 없습니다
모델 학습상황에서는 마치 절대 악과 같습니다

⭐ 다양한 해결방법들

이런 '악마'를 해결하기 위해 고대부터 다양한 방법들이 시도되었습니다
이중에서 가장 간단한 고대 마법은 batch size를 줄이는 것입니다
1. Batch size 줄이기
만약 256 배치사이즈를 128로 한번 줄여보고 다시 코드를 돌려보면
만약 Run! - Dobby is free!!
사실 이런 방법으로 해결하는 경우가 80%입니다 - 개인적으로요 ☺️
2. torch.cuda.empty_cache() 사용하기
그리고 코랩이나 주피터에서 코드를 실행할때 배치사이즈를 줄이고 다시 실행한다면
torch.cuda.empty_cache()를 사용해주어야합니다
GPU 메모리 안에서 사용하지 않는메모리 cache를 정리해주는 코드로
가용 메모리를 확보해줍니다
마치 청소마법과 같은 역할을 합니다
3. Batch size 실험해보기
앞에서 Batch size를 줄이는 것은 사실 아무런 연구 없이 그냥 사이즈를 줄이는 방법이었습니다
이를 좀더 효율적으로 줄이는 방법이 없을까요?
바로 사용가능한 Batch size를 실험해 보는 것입니다.
oom = False
try:
run_model(batch_size)
except RuntimeError: # Out of memory
oom = True
if oom:
for _ in range(batch_size):
run_model(1)이렇게 코드를 추가해주고 RuntimeError발생하면 해당 배치는 사용할 수 없는 거이죠
이런식으로 최대로 활용할 수 있는 배치 사이즈를 체크 할 수 있습니다
👍
4. GPUUtil & trainning loop에 tensor로 축적된 변수 확인 및 삭제
GPUUtil은 라이브러리로 특히 Colab 환경에서 메모리의 변화를 관찰할 수 있습니다
간단하게 아래 코드를 실행하면 적용해볼 수 있어요
!pip install GPUtil
import GPUtil
GPUtil.showUtilization()
그리고 또한가지
for i in range(batch_size): 안에서
tensor로 지정되어 있는 변수를 제거하는 것입니다
해당 변수 loop 안에 연산에 있을 때 GPU에 computational graph를 생성 되어 메모리를 잠식하게 되기 때문에
학습에 필요하지 않는 메모리를 차지하게 됩니다
'메모리를 먹는자들'인 것이죠

이런변수가 있다면 어떻게 해야할까요?>
간단하게 del이라는 제거마법을 활용해 주면 됩니다!!
del을 이용해서 해당 변수를 제거하는 것입니다
5. inference 시점에서는 torch.no_grad() 사용하기
그리고 추가적으로 모델의 추론 타임에서는 torch.no_grad()를 활용해주면 추론당시의 메모리를 줄일 수 있습니다.
즉, 추론때는 역전파를 하지 않기 때문에 굳이 메모리를 차지하고 있는 미분 값을 저장하고 있을 이유가 없는 것이죠
✅ 2. Mult-GPU
도비는 열심히 메모리를 관리해 보았지만...
메모리의 한계상 더이상 큰 모델을 학습시키기 힘들었습니다
그래서 도비는 그래픽 카드를 구매하려고 합니다 :)

그러나 도비는 가난한 집요정에 불과합니다...
그런 그에게 대용량의 비싼 GPU는 그림의 떡과 같습니다

다행기 저 위에 모델 보다 저렴한 ?! 모델을 발견했습니다
그리고 도비는 조금 무리해서 해당모델을 3개 구입했습니다
그런데 도비는 엄청난 문제를 마주쳤습니다
바로 Multi GPU를 학습하는 방법을 알지 못했기 때문입니다...
불쌍한 도비를 위해서 Multi GPU 학습 방법을 알아볼까요?👹👹
⭐Multi GPU의 개념
multi GPU의 개념은 아래와 같습니다
- Single vs. Multi
- GPU vs. Node - 시스템
- Single Node Single GPU
- Single Node Multi GPU
- Multi Node Multi GPU
간단히 말해서 Node는 컴퓨터 대수입니다
즉, Multi Node Multi GPU는 멀티 컴퓨터에 멀티 그래픽 카드입니다
당연히 최고의 방법은 Multi Node Multi GPU겠죠?
그러나 앞에서 말했듯이 우리 도비는 돈이 없습니다 😢😢
그러니 Single Node Multi GPU가 최선에 방법이겠죠 :(
⭐Model parallel vs. Data Parallel
Mutlit GPU 방법에는 크게 2가지가 있습니다
자세히 살펴볼까요??
1. 모델을 나누기
사실 모델을 나누는 것은 고대시대 때 부터 이미 진행되었습니다
익숙하시지 않나요??

바로 Alexnet입니다
하지만 Alexnet경우에는 당시GPU의 메모리가 3GB였기 때문에 ㅋㅋ
어쩔 수없는 병렬이었습니다
지금의 모델병렬은 조금 다릅니다
Transformer와 같이 대 용량 대 하이퍼 파라미터가 필요한 모델을 돌리기 위해서
지상 최고의 GPU 하나를 가져와도 부족할 것입니다
따라서 부득이하게 모델을 나눠서 넣을 수 밖에 없는 것이죠...
그러나 모델의 병목, 파이프라인의 어려움 등으로 인해 모델 병렬화는 고난이도 과제가 있습니다
2. 데이터 나누기
간단히 말해서 데이터를 나눠서 평균을 구해서 가중치를 업데이트를 해줍니다
minibatch 수식과 유사한데 한번에 여러 GPU에서 수행하는 것입니다
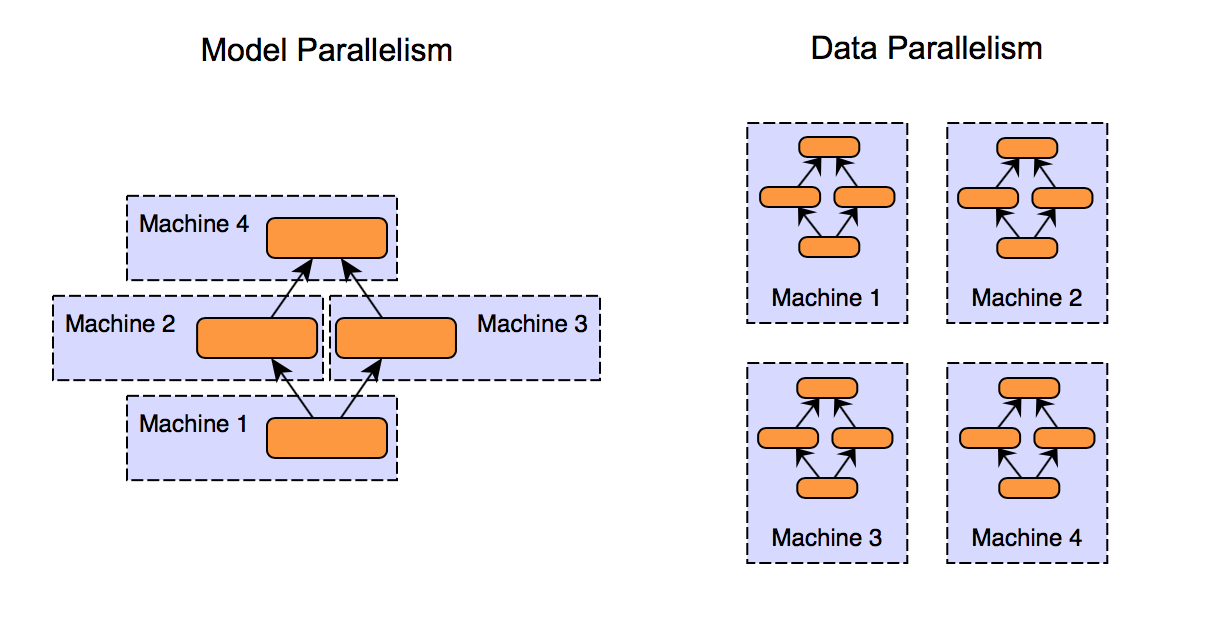
자세한 내용은 아래 포스팅을 참고해 주세요!!
딥러닝 모델의 분산학습이란? (Data parallelism과 Model parallelism)
지난 글(자연어처리 모델 학습을 위한 하드웨어 구성은? - NVIDIA Grace)에서 NLP 모델의 학습시 큰 모델 크기와 대규모 학습 데이터 때문에 여러 GPU에 나누어 연산하는 분산학습이 이뤄진다고 간단
lifeisenjoyable.tistory.com
⭐파이토치에서 분산 데이터 병렬 처리
파이토치에서는 DataParallel, DistributedDataParallel 방식을 제공합니다
둘의 차이점이 무엇이냐고요 ??
- DataParallel - 단순히 데이터 분해한 후 평균을 취함
→ GPU 사용 불균형 문제 발생, Batch 사이즈 감소 - 한 GPU가 병목, GIL
- DistributedDataParallel - 각 CPU마다 process 생성하여 개별 GPU에 할당
→ 기본적으로 DataParallel로 하나 개별적으로 연산의 평균을 냄
코드로 실행하는 방법은 간단합니다
#DataParallel
parallel_model = torch.nn.DataParallel(model) # 이게 전부?
#DistributedDataParallel
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data)
shuffle = False
pin_memory - True
trainloader = torch.utils.data.DataLoader(train_data, batch_size = 20, shuffle =False, pin_memoey = pin_memory, num_workers=3, sampler= train_sampler)
파이토치 공식 문서로 한번 연습해 볼까요???
분산 데이터 병렬 처리 시작하기
저자: Shen Li 감수: Joe Zhu 번역: 조병근 선수과목(Prerequisites): PyTorch 분산 처리 개요, 분산 데이터 병렬 처리 API 문서, 분산 데이터 병렬 처리 문서. 분산 데이터 병렬 처리(DDP)는 여러 기기에서 실행
tutorials.pytorch.kr
✅ 3. Hyperparameter Tuning
드디어 오늘의 마지막 단계에 도달했습니다
도비가 그래픽 카드도 사고 모델과 데이터도 분산해서 해결했습니다
그러나 도비는 아직 배가고픕니다

마지막 1%라도 짜내고 싶습니다!!
어떻게 해야할까요?
바로 아래의 3가지 방법이 있습니다
1 모델을 변경
2 데이터를 변경 또는 추가
3 Hyperparameter Tuning
그러나 앞에서 말했듯이 컴퓨팅 자원도 한정적이고 데이터도 한정적이면
시도할 수있는 방법은 하나밖에 없겠죠?? :)
딥러닝에서 조절할 수 있는 하이퍼 파라미터는 몇가지 없습니다
바로 learning rate, model size, optimizer 등입니다
물론 하이퍼 파라미터에 의해서 값이 크게 좌우되는 경우는 없습니다
하지만 1%라도 필요하죠...
그럴 때 시도한는 방법입니다
⭐Grid vs random & 베이지안 기반 기법

간단하게 말하자면 우리가 원하는 하이퍼 파라미터로 메트릭스를 만들어서
모델을 학습하여 비교하는 것입니다
하지만 하나 둘 손수 기록하면 귀찮죠?
우리가 코딩을 하는 이유는 무엇일까요????????
바로 마법을 쓰지 않고 마법같은 일을 하기 위해서 입니다.
당연히 Python 에는 위의 탐색방법을 쉽게 할 수 있는 라이브러리들이 있습니다
그중에서도 Ray가 괜찮은 라이브러리입니다

우리가 저번 시간에 배운 Tensorboard와 같이 시각화 툴을 함께 사용해준다면!!
모델 비교도 쉬워 지겠죠?
Python Ray 사용법 - Python 병렬처리, 분산처리
파이썬 병렬처리를 위한 Python Ray 사용법에 대한 글입니다 키워드 : Python Ray for multiprocessing, Python Parallel, Distributed Computing, Python Ray Core, Python Ray for loop, Python ray example 해당 글은 단일 머신에서 진
zzsza.github.io
한번 연습해볼까요??
공식 github 코드
GitHub - ray-project/ray: Ray is a unified framework for scaling AI and Python applications. Ray consists of a core distributed
Ray is a unified framework for scaling AI and Python applications. Ray consists of a core distributed runtime and a toolkit of libraries (Ray AIR) for accelerating ML workloads. - GitHub - ray-proj...
github.com

오늘 도비와 함께 떠나는 딥러닝 모델이 어떠했나요??
정말 이 속도면 딥러닝 요정이 되지않을까? 생각해 봅니다...
그럼 다음 수업시간에 만나요 이만 :)
🖐️
'네이버 부스트캠프 🔗 > ⭐주간 학습 정리' 카테고리의 다른 글
| [부스트 캠프]Week 2 회고 및 Week 3 목표 정리 (0) | 2023.03.20 |
|---|---|
| [네이버 부스트 캠프 AI Tech] VGG 논문리뷰 (0) | 2023.03.17 |
| [네이버 부스트 캠프 AI Tech] Pretrained Model & Training Monitoring (2) | 2023.03.15 |
| [네이버 부스트 캠프 AI Tech] Pytorch nn.Module & Dataset (0) | 2023.03.14 |
| [네이버 부스트 캠프 AI Tech] Pytorch 기본 (0) | 2023.03.13 |