본 글은 네이버 부스트 캠프 AI Tech 기간동안
개인적으로 배운 내용들을 주단위로 정리한 글입니다
본 글의 내용은 새롭게 알게 된 내용을 중심으로 정리하였고
복습 중요도를 선정해서 정리하였습니다

✅ Week 2
오늘은 특별히 수업 내용이 없습니다
이미 어제 도비는 모든 수업을 들었기 때문입니다
따라서 오늘 활동한 내용중에서 논문 리뷰의 핵심 내용을 정리하겠습니다
✅논문리뷰 - Very Deep Convolution Networks for Large-Scale Image Recognition
논문 링크 :
Very Deep Convolutional Networks for Large-Scale Image Recognition
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x
arxiv.org
✅VGGNet Architecture

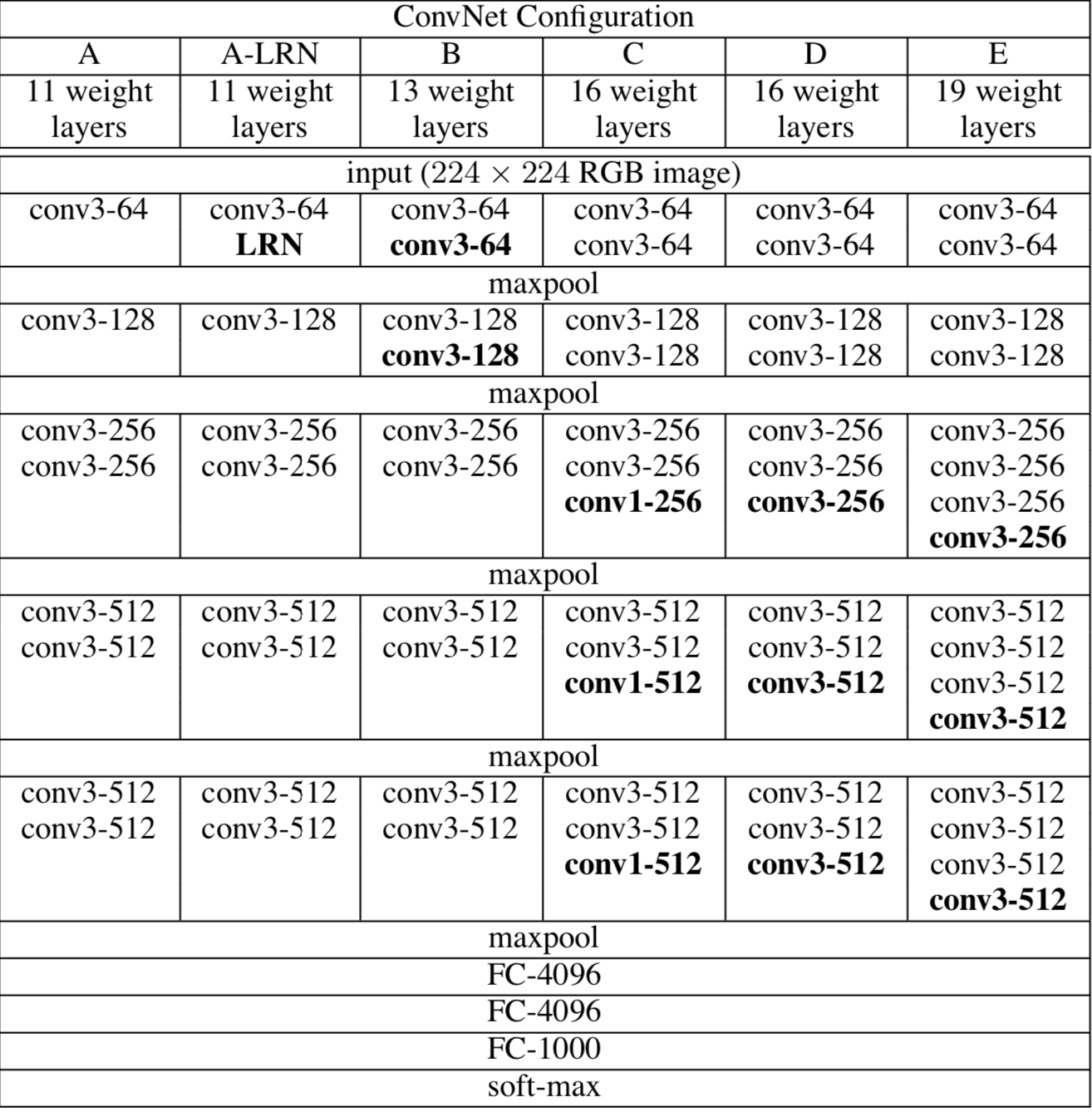
VGGNet 논문에 나오는 모델은 다음과 같다
비슷한 형태의 모델을 구성해서 깊이와 레이어의 종류만 살짝 변화를 주어서
레이어의 깊이가 모델의 정확성에 어떠한 영향을 미치는지 실험을 한 것이 본논문의 핵심이다
즉, 이 논문의 핵심은 모델의 깊이의 영향 측정에 있다
쉽게 말해서 기존 AlexNet같은 CNN의 경우에는 레이어의 수는 7~9개로 볼 수있다
반면 본 논문에서 소개하는 VGGNet 같은 경우 16~19까지 레이어의 수를 늘린다
✅3x3 filter
사실 지금의 관점에서 VGGNet의 핵심은 3 x 3 filter에 있다
이전 AlexNet이나 다른 CNN의 경우 첫 번째 레이어에서 11 x 11 이나 7x7의 큰 필터 사이즈를 사용해서
Convolution 연산을 진행했다
그러나 본 논문에서는 이러한 큰 사이즈의 필터보다는 3x3 filter를 사용할 것을 주장한다
3x3 filter를 2개 쌓는 것은 5x5 filter 1개의 수용범위와 같고
개는 7x7 filter 1개의 수용범위와 같다
사실상 지정되는 관찰되는 범위가 같다는 것이다
그렇다면 그냥 5x5 하나쓰면 되지 않은가?
아래의 두 가지 이유가 3x3 필터에 효용성을 추가해준다
1. 학습 파라미터 수가 줄어든다
1. 학습 파라미터 수가 줄어든다부터 살펴보자
간단하다
직접 계산해보면 된다
3x3 필터 3개를 사용할 때와 7x7 필터 하나를 사용할 때 비교해보자
3x3 필터 3개를 활용하면 3(3x3xC)가 된다 즉 27C 가되는 것이다
반면, 7x7 필터 1개를 활용하면 파라미터는 7x7xC가 된다 즉, 49C가 된다
따라서 같은 수용범위라면 3x3 필터를 사용하는 것이 파라미터 수를 줄이는 입장에서 이익이다
2. 비선형성을 추가해줄 수있다
이것에 대한 답변은 간단하다 convolution filter를 더 많이 사용하면
사이에 비선형 함수 = 활성화 함수를 더 많이 사용할 수 있게 된다
이 말은 비선형성을 더 추가 해줄 수 있음을 의미한다

이 말은 비선형 함수를 더 많이 추가함으로써 조금더 섬세하게 특징을 추출할 수 있음을 의미한다
더 큰 필터를 지난 경우에는 더 큰 지역을 0 또는 그 보다 큰값으로 변화 시키지만
3x3 필터의 경우에는 조금더 적은 지역들로 0 또는 그보다 큰값으로 변화 시킨다
- ReLU를 사용했을때를 가정한다면.. - AlexNet 이후 ReLU는 일반적으로 사용되었다-
따라서 더 많은 비선형 성을 추가해주면 모델이 더욱더 잘 학습될 가능성이 증가한다
1.정리하자면 3x3 filter를 사용함에 따라서 학습 파라미터 수가 줄어들었기 때문에 더 깊은 모델을 만들 수 있었고
2.또한 비선형성을 더욱 추가함으로써 정확성 높은 모델을 만들 수 있었던 것이다
사실 VGG 핵심은 이게 끝이다
학습 방법은 Local Response Normalization을 사용하지 않은 것 빼고는
AlexNet 모델과 비슷하기 때문이다
이는 기존 SOTA 모델들의 방법을 활용하더라도 모델의 깊이만 추가해주면 성능이 좋아진다것을 증명하기 위해서이다
추가+) VGG 모델의 구조는 뒤 나올 ResNet의 Backborn 모델의 역할을 하였다
VGG에서 Convolutional 연산을 할 때 같은 블록에서 나오는 output의 W H는 padding을 1로 해주고 stride를 1로 3x3를 쓰면 유지가 되기 때문이다
따라서 ResNet에서 Identitiy Mapping을 해주기가 쉽다
즉, VGG 모델은 깊은 레이어의 성능 향상의 가능성을 제시해 주었고
이러한 가능성을 이어서 실제적으로 매우 깊은 모델 - ResNet 논문에서는 1000개 레이어
을 학습할 수 있는 방법인 Resiual connection이라는 방법에도 영감을 주었다
그만큼 중요한 CNN 역사에서 중요한 역할을 한 논문이다
오늘은 특별히 수업 내용보다는
논문 리뷰 스터디를 한 내용을 정리하였다
논문이 자연스럽게 이어지는 그 날까지 열심한번 달려보자!!

'네이버 부스트캠프 🔗 > ⭐주간 학습 정리' 카테고리의 다른 글
| [네이버 부스트 캠프 AI Tech] Model Optimizer & Regularization (0) | 2023.03.20 |
|---|---|
| [부스트 캠프]Week 2 회고 및 Week 3 목표 정리 (0) | 2023.03.20 |
| [네이버 부스트 캠프 AI Tech] OOM & Multi GPU & Hyper parameter tune (0) | 2023.03.16 |
| [네이버 부스트 캠프 AI Tech] Pretrained Model & Training Monitoring (2) | 2023.03.15 |
| [네이버 부스트 캠프 AI Tech] Pytorch nn.Module & Dataset (0) | 2023.03.14 |