본 글은 네이버 부스트 캠프 AI Tech 기간동안
개인적으로 배운 내용들을 주단위로 정리한 글입니다
본 글의 내용은 새롭게 알게 된 내용을 중심으로 정리하였고
복습 중요도를 선정해서 정리하였습니다

✅ Week 3
목차
- CNN Models
- Computer Vision Applications
✅ Intro

다시 돌아온 도비와 함께 떠난 딥러닝 공부.. 😢
도비는 이미 Image Classification 모델을 학습해봤기 때문에
CNN모델에 대해서 어느정도 알고있다
그러나 도비는 다양한 CNN 모델들을 알고 싶어졌다
그리고 도비가 한번도 경험 하지 못한 Image task 분야가 존재한다는 것을 알게 되었다
오늘의 2편에서는 도비와 함께 다양한 CNN 모델을 자세히 알아보고 다른 image task를 알아보자!!
1. CNN Models
사실 AlexNet 이전보다 먼저 존자한 LeNet5같이 선조 모델이 존재한다
그러면 왜 AlexNet을 사실상 CNN의 시작점이라고 볼까
이는 AlexNet이 우승한 2012년도로 거슬러 올라가야한다
당시 이미지넷 대회에서 AlexNet이전에는 우승한 모델들을 보면 CNN은 존재하지 않았다
SVM과 전통 머신러닝을 조합한 방법들이 상위권을 차지했다
그러나 2012는 AlexNet이 이미지넷을 우승하면서 모든 판이 뒤집혔다
AlexNet 등장이후 CNN 모델이 - 딥러닝이라는 표현이 맞겠다
우승을 놓친적이 없다
그만큼 강력한 방법론으로 자리를 잡은것이다
✅ Alexnet

AlexNet 구조를 보면 위의 사진과 같다 - 진짜 지겹도록 본다🥲
사실 지금와 AlexNet의 방법론은 크게 놀랍지 않다
하지만 당시에 AlexNet 논문에 나오는 내용은 최.신.기.술 이었다
AlexNet의 특징을 정리하면 아래와 같다
1. ReLU 함수 이용
- 당시에는 Sigmoid, tahn같은 활성화 함수가 주류였다
하지만 AlexNet이 ReLU 함수를 사용하고 나서 거의 대부분 ReLU 함수나 그 계열의 활성화 함수를 사용하게 되었다
2. GPU 2대 사용
- 당시의 GTX580은 메모리가 3gb으로 딥러닝을 돌리기에는 턱없이 부족한 모델이었다
그래서 어쩔 수 없이 2대의 그래픽 카드로 학습을 돌릴 수 밖에 없었다
지금의 Multi GPU의 목적과 조금? 다른 느낌이다
3. LRN - Local Response Normalization
사실 요즘은 잘 사용되지 않는 기술이다

위의 사진을 보면 검은색 점이 사이마다 보이는 착각이 들것이다
이는 주변 뉴런의 영향을 받아 생기는 현상인데
딥러닝 모델의 경우 특히, ReLU를 사용하면 이러한 현상이 생길 수 있다고 한다
따라서 주변 뉴런의 영향을 줄이기 위해서 Local Response Normalization을 활용한것이다
쉽게 말하자면 주변의 영역을 선택해 정규화 하는 방법이다
4. Data augmentation
요즘 CNN 모델을 학습할 때도 필수적으로 해야하는 방법중 하나로 앞에 시간에서 배운내용이다...
벌써 잊지 않았길..😢😢
5. Dropout
FullyConnected Layer에서 실행하는 방법으로 무작위로 뉴런을 끊는다
이러한 방법을 통해서 다양한 모델을 생성해볼 수 있다
따라서 이러한 방법으로 과적합을 막을 수 있다 - 물론 학습과정에서만 이루어진다

✅VGG Net & GoogleNet
VGG net과 Google net은 같은 해에 나온 모델로 Googlenet이 이미지넷 대회 1등 VGGnet이 2등을 했다
두 모델의 핵심 아이디어는 조금 차이가 있지만 AlexNet에 비해 모델을 깊게 만든다는 공통점도 있다
VGGNet

VGG net의 핵심은 3x3 필터를 사용했다는 것에 있다
왜 3x3 필터를 사용하면 모델을 깊게 만들 수있을까?
3x3 필터를 2개 쌓는것은 5x5 필터 하는 쌓는것과 같은 수용범위를 같는다
직관적으로 이해되지 않겠지만 계산해보면 같다
그렇다고 3x3 필터 2개를 이용해야하는가? 그냥 5x5 하나쓰는게 더 쉽지 않을까?
아니다
당연히 또다른 장점이 있다
바로 1) 파라미터 수가 줄어든다
실제로 계산해보더라도 3x3 2개가 5x5 1개 보다 모델의 파라미터 수가 적다
또다른 장점도 있는데 2) 비선형성을 추가할 수있다
두 레이어 사이에 ReLU함수나 활성화 함수를 추가함으로써 비선형성을 추가할 수 있는 것이다
비선형성을 추가하면 feature map을 조금더 부분적으로 특징을 추출할 수 있다
GoogleNet

GoogleNet의 핵심은 inception module이다
위의 사진은 너무 복잡하니 확대해서 보자

쉽게 말해서 다양한 필터를 하나의 레이어로 묶어서 사용했다
이렇게 하면 다양한 필터에서 뽑을 수 있는 특징을 추출할 수 있고
다양하게 설명이 가능해진다
또한 이런경우 모델이 깊어지면 차원이 커져 파라미터 수가 증가하게 되는 단점이 있을 수 있다
이럴때 1x1 filter가 활용되는데
이를 bottleneck이라고한다
1x1은 어떠한 효능, 효과 있을까?

당연히 파라미터 수를 줄여주는 효과가 있다
input과 output 차원을 유지한채
파라미터 수를 줄이는 매우 좋은 결과를 도출할 수있다
위의 사진을 예시로 보다라도 거의 30%로 줄어든것을 확인할 수있다

✅ResNet
다음으로 등장한 모델은 ResNet이다
사실 ResNet은 앞의 Vgg, Googlenet처럼 엄청난 성능 개선을 만들지는 않았다 - 사실 올라갈 만큼 올라간 상황이라 그러지 않을까?
하지만 ResNet이후 인간의 능력을 딥러닝 모델이 초월하게 되었고
ResNet의 방법론은 더 깊은 모델을 학습할 수 있게 만들어 주었다

ResNet 등장이전에는 깊은 모델이 더 학습이 안되는 결과가 있었다
따라서 이를 학습시킬 방법이 필요했다
카이밍 허는 이러한 방법에 Skip connection 이라는 개념을 도입해서 모델의 학습 성능을 향상시켰다

Skip connection 개념은 간단하다
convolution layer 지나온 값에 지나가긴 전 X값을 추가해주는 것이다
이러면 어떠한 효과가 있을까?
바로 모델이 H(x)에서 x를 뺀 값만 학습하면된다
즉, F(x) = 레이어를 지나는 식이 0이 되면 H(x) = 전체식이 x가 되기 때문에 - 우리가 목적하는 방향
F(x)가 0이 되는 방향으로 학습하면되기 때문에
모델이 아무리 깊어져도 방향을 잃지 않고 학습이 잘되는 것이다
실제로 논문에서도 1000층을 쌓을 수 있다고 주장했다
또한
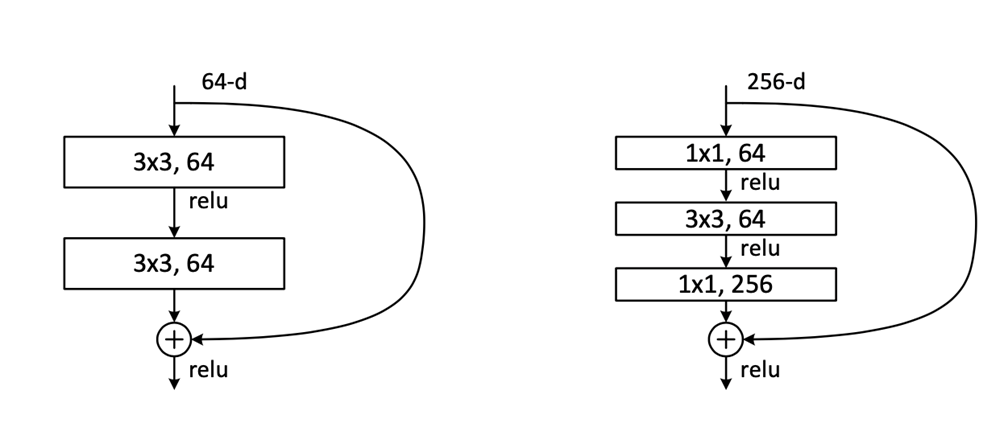
1000층 이상의 모델을 학습시키기 위해서는 bottlenect 구조가 필요했는데
ResNet은 이를 도입했다
즉, 이러한 방식으로 차원이 매우 깊어져도 파라미터가 기하급수적으로 증가하는 결과를 막으면서
모델을 학습시킬 수있었던 것이다

2. Computer Vision Applications
위의 모델들은 대부분 분류문제에서 다루어졌다
물론 꼭 분류에서만 다루어진것은 아니다
그러면 어떤 다른 task가 있을까?
지금부터 알아보자

✅Semantic Segmentation
Semantic Segmentation은 간단하게 말하면
이미지 픽셀마다 종류를 분류하는 문제이다

특히 자율 주행에서 많이 사용되는 task로 다양한 모델들이 있다
👍Semantic Segmentation모델들 - 모델들의 자세한 방법은 논문리뷰로 찾아오겠습니다 :)
- Unet
- FCN
- Mask R-CNN ...
핵심은Fully Convolutional, Deconvolution (Conv tranpose)을 활용한다는 것이다
Fully Convolutional의 경우에는 기존 Fully Connected 와 파라미터 수는 같지만 결과는 다르다

이런식으로 Convolution 연산을 통해서 공간정보를 유지한채 이미지의 라벨을 구별하는 것이다
하지만 이러한 방법은 input의 크기 감소를 불러온다 - convolution이 진행될 수록 이미지는 줄어들기 때문에
따라서 이미지를 다시 늘려줄 방법이 필요하다
이러한 방법을 Deconvolution이라고 한다
Deconvolution 이란 무엇인가?
Deconvolution CNN에서 convolution layer는 convolution을 통해서 feature map의 크기를 줄인다. 하지만 Deconvolution은 이와 반대로 feature map의 크기를 증가시키는 방식으로 동작한다. Deconvolution은 아래와 같은 방
3months.tistory.com
쉽게 말하자면 convolution 연산의 역이다
zero-padding을 해주고 여기에 연산을 해서
이를 통해서 feature map의 크기를 늘리는 것이다
✅Object detection
두번째 task로는 object detection이 있다
쉽게 말해서 이미지나 영상에서 객체를 탐지하는 것이다
대부분이러한 방법은 Bounding Box를 통해서 객체의 위치를 탐지하고
이렇게 탐지된 객체의 클래스를 판별하는 방법으로 나누어진다
초기 방법으로는 R-CNN이 있는데
이는 bounding box를 만들고 CNN을 진행해 분류하는 과정이었다
그러나 bounding box가 너무 많았기 때문에 CNN 연산이 너무 많아서 현실에 적용하기 힘들었다
이러한 방법을 해결하기 위해서 등장한것이 SPPNet인데
이는 이미지에서 CNN 연산을 한번만돌리고 여기에 Bounding Box에 해당하는 값을 추출하는 것이었다
하지만 이러한 방법도 bounding box가 많으면 feature 추출에 많은 시간이 소요 되었다
결국 Fast R-CNN, Faster R-CNN, Yolo 방법등 속도를 올리는 다양한 방법들이 등장하게 되었고
YOLO같은 경우에는
baseline : 45 fps, smaller version : 155fps으로 최근 나오는 버젼같은 경우에는 현실 task에서도 많이 적용된다
-이것에 대한 자세한 내용도 논문 리뷰로 정리해보겠다 🔥🔥🔥

오늘 하루종일 도비와 함께 너무 많은 내용을 배워서 버리가 어질어질하다...
그래도 언젠간 딥러닝의 요정이 되기 위해서 도비는 일해야한다

도비가 해방되는 그날까지 딥러닝 여정은 계속된다....
'네이버 부스트캠프 🔗 > ⭐주간 학습 정리' 카테고리의 다른 글
| [네이버 부스트 캠프 AI Tech] Transformer (0) | 2023.03.21 |
|---|---|
| [네이버 부스트 캠프 AI Tech] RNN & LSTM & GRU (0) | 2023.03.21 |
| [네이버 부스트 캠프 AI Tech] Model Optimizer & Regularization (0) | 2023.03.20 |
| [부스트 캠프]Week 2 회고 및 Week 3 목표 정리 (0) | 2023.03.20 |
| [네이버 부스트 캠프 AI Tech] VGG 논문리뷰 (0) | 2023.03.17 |