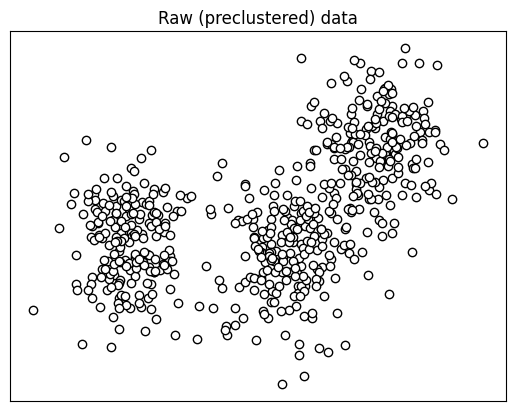
오늘은 K-평균 알고리즘 (K-Means)를 Python으로 직접 구현해 보겠다 필요한 라이브러리는 Numpy 하나이다 K-Means 알고리즘의 과정을 순서대로 나타내면 아래와 같다 1. 데이터 공간에서 임의의 k개 중심점을 초기화 한다 (랜덤 선택), 여기서 중심은 클래스 또는 범주에 해당한다. 즉, 이 중심점을 기준으로 해당 데이터의 클래스가 결정되는 것이다. 이때, k는 하이퍼 파라미터로 직접 지정해주어야한다. 2. 각 데이터 관측치와 각 중심 사이의 유클리드 거리를 계산한다. - 모든 데이터와 각 중심점 사이의 각각 거리를 구하는 것 3. 각 데이터 관측치를 가장 가까운 중심의 그룹에 할당한다 - 즉, k=3이라고 가정을 한다면 1점과 data들의 거리 2점과 data들의 거리, 3점과 데이터의 ..